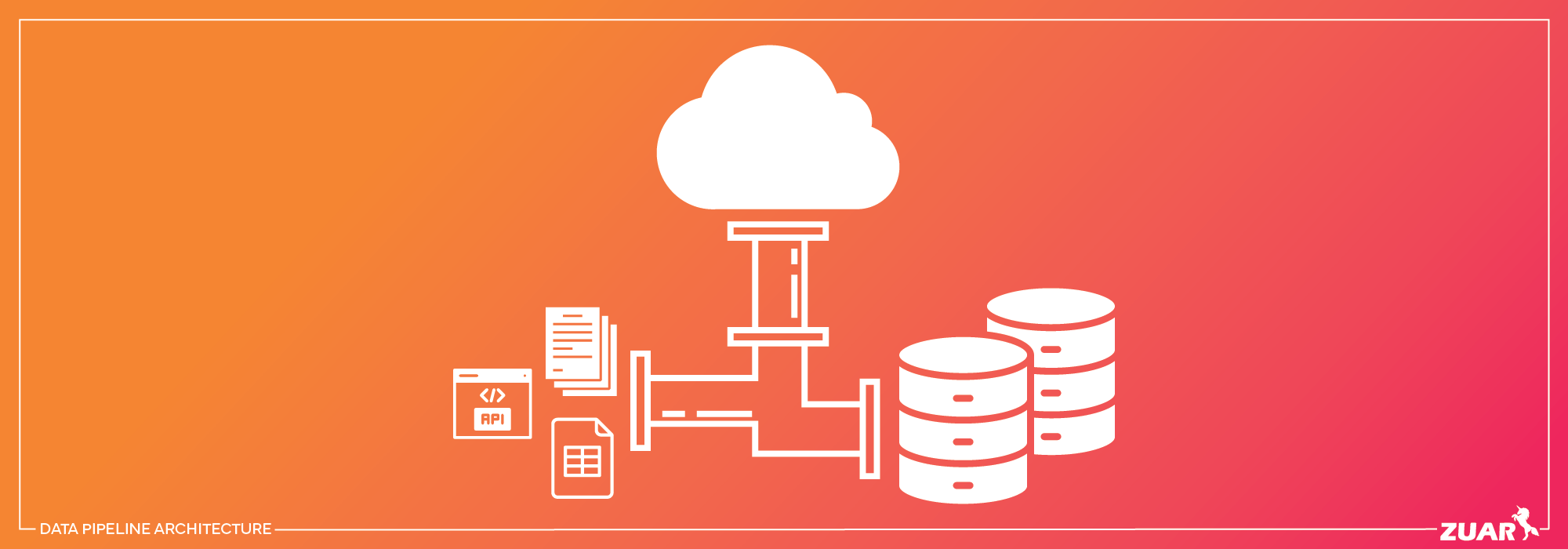
Overview
Data pipeline architecture is the backbone of modern data-driven businesses. It enables organizations to harness the power of data, transforming raw information into actionable insights that guide decision-making.
But what exactly is a data pipeline architecture, and how can you build an efficient, reliable, and scalable one?
Stick around, and you’ll find out the secrets of designing effective data pipeline architectures that will propel your organization to new heights of success.
Key Takeaways
- Data pipeline architecture is an approach to managing data through its life cycle, from generation to storage and analysis.
- Components of a Data Pipeline include data sources, ingestion, transformation, destinations, and monitoring which support automation.
- Automation frameworks and templates provide efficient results while real-time monitoring strategies ensure successful error handling for reliable pipelines.
Related Article:
 Team Zuar
Team Zuar

Understanding Data Pipeline Architecture
A data pipeline is a process used to manage data throughout its life cycle, from generation to analysis, use as business information, storage in a data warehouse, or processing in a data analytics model.
A data pipeline is structured in layers, with each subsystem providing an input to the subsequent stage until the data reaches its destination, ensuring a smooth data flow.
Components of a Data Pipeline
Data sources, ingestion, transformation, destinations, and monitoring are fundamental components of a data pipeline and contribute significantly to data analytics automation.
Data is extracted from various sources, such as data lakes, databases, and APIs, and transformed into the desired structure using data automation tools and techniques (such as data connectors).
A data warehouse serves as a centralized repository for an enterprise’s cleansed and standardized data, enabling the utilization of analytics, reporting, and business intelligence.
On the other hand, a data lake is utilized for less-structured data and is accessible to data analysts and data scientists. Both data warehouses and data lakes play crucial roles in modern data management strategies.
Types of Data Pipelines
Data pipelines can be broadly classified into two types: batch processing pipelines and real-time/streaming data pipelines.
Raw data load is the most basic form of data pipeline but is also the least efficient and can be challenging to sustain. ETL (Extract, Transform, and Load) is more efficient than raw data load; however, it may be more intricate to configure and sustain.
ELT (Extract, Load, Transform) is more efficient than ETL but demands more resources and can be more challenging to maintain.
ELT is often preferred over ETL in modern data integration scenarios because ELT takes advantage of the increased processing power and storage capacity of modern data warehouses.
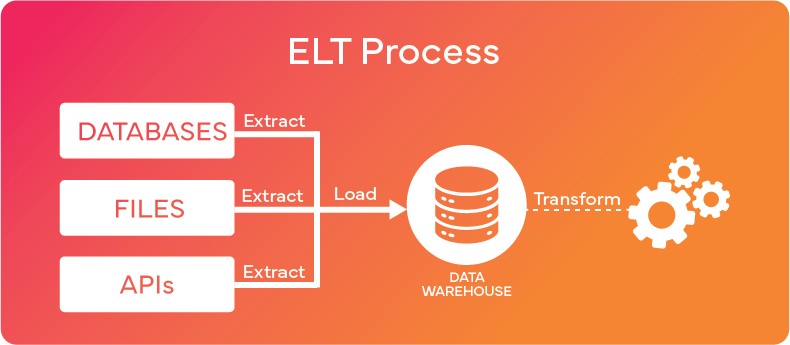
One data pipeline platform that takes the ELT process is Zuar Runner, an end-to-end solution that can collect, transform, model, warehouse, report, monitor, and distribute all your organizational data. Learn more...

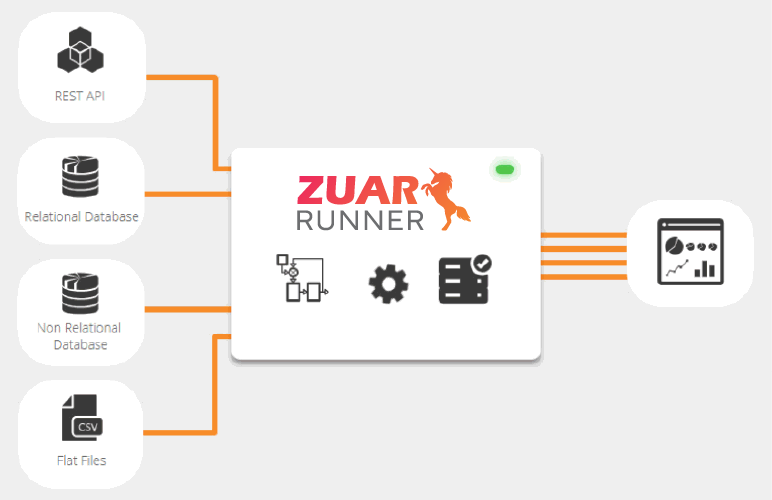

Building an Effective Data Pipeline
Choosing the right data sources, deciding between ETL and ELT, and considering data virtualization and stream processing techniques are vital steps to building a successful data pipeline.
Scalability and performance are essential for data automation, as they guarantee enhanced performance and scalability of the data environment.
Automated data integration tools can facilitate analytical speed by enabling data scientists to perform analytics more expeditiously and by executing complex and time-consuming tasks efficiently.
Selecting the Right Data Sources
In a data pipeline, data sources function like wells, lakes, and streams, supplying the necessary data for ingestion and movement through the pipeline.
The quality of the data from these sources should not be overlooked, as it directly influences the accuracy and reliability of the final output.
Ensuring access to high-quality data sources is a critical factor in driving data-driven decision-making and extracting valuable insights from the data extracted.
Choosing Between ETL and ELT
Choosing between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) is influenced by factors like data volume, processing requirements, and the preferred output format.
In ETL, data is modified before loading it to its destination, while in ELT, data is loaded without executing any transformations.
Understanding your organization’s requirements and constraints will help you make the right choice between these two approaches, ensuring an efficient and reliable data pipeline.
Learn more about the differences between ETL and ELT and how Zuar Runner optimizes data integration:

Data Pipeline Technologies and Techniques
Businesses have the option to either create their own data pipeline code or use Software-as-a-Service (SaaS). The latter provides a more manageable alternative to writing custom code, boasting easy setup and limitless data volume.
Another innovative approach to handling large volumes of data in real-time is through data virtualization and stream processing techniques.
SaaS Data Pipeline Solutions
SaaS data pipeline solutions, such as Zuar Runner, offer a more manageable alternative to writing custom code, with easy setup and unlimited data volume.
Organizations no longer need to compose their ETL/ELT code and construct data pipelines from the ground up, as SaaS solutions streamline the process and minimize development time.
Data Virtualization and Stream Processing
Data virtualization is a technique that enables access to data from multiple sources without requiring data movement or replication, providing a layer of abstraction that simplifies data access and integration.
Stream processing, on the other hand, is a technique that facilitates real-time processing of data as it is being received, making it ideal for handling continuous data streams from IoT devices and sensors.
Both techniques allow for real-time data processing and analysis, empowering businesses to make data-driven decisions with the most up-to-date information available.

Ensuring Data Quality and Reliability
The success of a data pipeline heavily relies on data quality, which ensures the accuracy and reliability of the final output. To maintain data quality and reliability in a data pipeline, data validation, QA, and repeatable processes are crucial.
Data validation is the process of ensuring that the data is accurate and complete. This can be
Data Validation and Quality Assurance (QA)
Ensuring data quality at both the source and destination is crucial for a successful data pipeline. Validation checks and alerts can be implemented to identify and address any issues that arise, making it easier to maintain the integrity and accuracy of the data throughout the pipeline.
Repeatable and Idempotent Processes
ETL/ELT pipelines should be designed to produce consistent results, with repeatable and idempotent processes ensuring data accuracy and reliability.
Repeatable processes are those that consistently yield the same output when provided with the same input, while idempotent processes are those that generate the same output regardless of the number of times they are executed.
Utilizing these processes in ETL/ELT pipelines guarantees data precision and dependability, as well as diminishes the danger of blunders and data loss.

Factors to Consider When Choosing an Architecture
Choosing a data pipeline architecture requires consideration of several factors including:
- Data volume
- Scalability
- Storage
- Real-time requirements
Understanding your organization’s requirements and constraints will help you make the right choice for your data pipeline architecture, ensuring an efficient and reliable solution.
Additionally, the GCP cost calculator can be utilized to assist with cost analysis of the solution in advance.

Implementing Data Pipeline Architecture
Ready to build a robust and efficient data pipeline that powers your organization's data-driven decisions? Look no further than Zuar, your trusted partner for data pipeline architecture and services.
Use Zuar Runner to automate the flow of raw data from a wide variety of disparate data sources into a single destination for analytics, fully prepped and ready for use.
As an end-to-end solution, you aren’t forced to spend time and money connecting a variety of pipeline tools to form a complete solution; you get it all with Zuar Runner.
Additionally, Zuar's team of data experts will guide though the process of designing your data pipeline architecture, identifying the tools you need, implementing your automated data pipeline, and offering long-term support.
Schedule a consultation with us today to start designing a data pipeline that propels your business forward with Zuar's top-tier solutions and services:

Frequently Asked Questions
What is data pipeline architecture?
Data pipeline architecture is a system that captures, organizes, and routes data from multiple sources to make reporting, analysis, and using data easier. It enables users to gain valuable insights from the raw data by reducing complexity.
What is an example of a data pipeline architecture?
An example of a data pipeline architecture is the Lambda Architecture, which combines batch and streaming pipelines to enable both real-time streaming use cases and historical batch analysis.
What are the main 3 stages in data pipeline?
Data pipelines involve three stages: gathering data from a source, transforming it with processing steps, and finally sending the results to a destination. This process is know as ETL (extract, transform, load).
What is an example of data automation?
Data automation is a common tool used in many businesses today, such as with ETL processes, that allow for efficient extraction of data from various sources, transformation into a usable format, and then loading into systems accessible to end users - all without manual intervention.
