What is Data Ingestion?
As the data landscape matures, it has become critical that organizations utilize data in their decision making processes. As such, the competitive landscape is mandating that such organizations implement data-driven processes to remain competitive.
Data ingestion is the process of taking data from a source, whether internal or external, and extracting it to a target (most often cloud storage or a data warehouse). The data lake, an architecture which has recently mushroomed in popularity, relies on the ability to quickly and easily ingest a broad swath of data types.
At the start of data pipelines is the ingestion of data from external sources. This data is used to enrich internal data or create value from data science and machine learning processes.
In this article, we’ll discuss data ingestion in the context of the modern data stack, the importance of a solid data ingestion framework, the types and formats of data that may be ingested, and present your options for implementing a scalable solution. To wrap up, we’ll provide a glimpse into the future of data ingest.
Data Ingestion in the Modern Data Stack
The modern data stack (MDS) is a term used to describe the recent proliferation of data tooling. Data operations have reached a maturity where almost every component of a traditional data workflow can be procured through SaaS or implemented via an open-source alternative. This is known as the modern data stack.
There are now entire websites, podcasts, books, and much discussion around how to best manage technology that underlies the stack. While this can quickly become a rabbit hole, it’s important to understand how the technology we’ll focus on today fits into this context. Data ingestion is merely one step in a series of processes used to manage data infrastructure at scale.
ETL vs. ELT
ETL/ELT is a concept core to data ingestion. You can read this in-depth synopsis, but we’ll briefly summarize here to provide background. ETL stands for 'Extract Transform Load.' It used to be the case that data storage was sparse—each company required a physical server to load data, so upgrading a database was a costly and time-consuming operation. Often one that required procuring new physical components like more RAM, better processors, etc.
As such, that data had to be transformed prior to being loaded to save space and ensure that only the highest quality data was being stored. Hence, the process of ETL naturally evolved in the 1980s and '90s as one of necessity.
Today, databases are almost always cloud-hosted. The cost of cloud storage has fallen tremendously, and many warehouses are now serverless. The cost of storing data has never been lower. Thus, most teams adopt an ELT framework, “Extract Load Transform.”
This is a “store first, analyze later” approach that usually involves extracting almost all information to cloud storage, like Amazon S3 or Google Cloud, in a semi-structured or unstructured format, then selectively loading a portion of that to a data warehouse and performing transformations for analysis.
While there are numerous implications for ELT compared to ETL, most obvious is probably that the volume of data being loaded is much larger than an ETL approach.
Couple that with the explosion of data tracking and processing improvements in the last two decades, and it’s obvious why data ingestion is a crucial part of the data framework.
There are two direct applications for having a quality data ingestion pipeline.
- Data Transformation: data transformation is the process of manipulating, combining, and otherwise parsing data for consumption by analytics, science, and other business users. Being able to appropriately transform and catalog data requires consistently ingested data. Having a robust ingesting framework is crucial to the transformation process and helps to establish trust with stakeholders in timely and accurate data.
- Data Analytics & Business Intelligence: The old data maxim is “garbage in, garbage out.” The quality of ingested data will directly impact the quality of analysis and business intelligence. For this reason, it’s essential to provide reliable, accurate, and clean data through the transformation process.

Data Ingestion Types & Pipelines
There are several ways to think about data ingestion and pipeline types, but we’ll provide three main variables in ingestion tooling and analyze their implications: structured vs. semi-structured data, serverless vs. serverful solutions, and batch vs. stream processing.
Structured vs. Semi-Structured
Data is most commonly ingested in either structured or semi-structured form. Semi-structured data is data that does not have a rigid schema, like JSON or XML.
Semi-structured data is often comprised of key/value pairs that allow for the representation of loosely-formatted hierarchical information. The use of semi-structured data has grown in the past decade thanks to its flexibility and ease of use.
While semi-structured data may be easy to create, it isn’t necessarily easy to store. Data warehouses like Amazon Redshift only accept structured data, that is, data that conforms to a schema and always contains the expected types.
When ingesting data, it’s important to consider the structure and how it will play with your data targets. A popular pattern is writing semi-structured data to a file storage system, like Amazon S3 or Google Cloud Storage, then performing the necessary transformations to process semi-structured data into structured data before sending it to a warehouse.
However, a growing number of data warehouses are building support for writing semi-structured data to a column with the ability to then unpack that data into a table or view downstream. Google BigQuery is a good example.
Serverless vs. Serverful
The de-facto standard in copying data is a serverful process. Serverful processes require the deployment of compute resources to run jobs, which process data from one destination to another.
However, a number of new and forthcoming processes are serverless—Snowflake’s Snowpipe being one such example. In a serverless process, resource management is handled by the platform, not the data application.
Serverless processes run immediately and scale almost instantaneously, whereas serverful processes often require delays so compute resources must be assigned and scaled appropriately.
A caveat: serverless processes can rapidly incur unnecessary costs if improperly managed. It’s important to understand the pricing structure for any solution that your team chooses to implement.
Batch vs. Stream
Batch vs. stream processing refers to the frequency at which a data pipeline processes information. This is often dependent on the needs of the application or business process ingesting the data. Fresher data necessitates an increased cost, as pipelines will need to run more frequently.
Batch processes operate on bulk data, taking each chunk on a scheduled basis. An example is an ELT pipeline that processes new data from a production read-replica once per day. Streaming processes, by contrast, operate continuously on one event at a time, or at an interval (micro-batches). An example of stream data might be processing website events (clicks) in real-time.
As we mentioned, the business need should define the solution when choosing between batch and stream processing. Cost, complexity, and engineering resources are all factors when deciding between these choices.

Build vs. Buy in Data Ingestion
As data ingestion tooling has matured, the build/buy decision has become more nuanced. Today, there exist a number of off-the-shelf data pipeline tools that drastically reduce the complexity of data ingestion, which have prebuilt connectors for transporting raw data from popular source targets.
Why Most Companies Choose Packaged Solutions
A few years ago, most orgs had data engineering teams that constructed every data pipeline from scratch. That is no longer necessary. Most teams should opt for a packaged solution for common connections. Why? The connectors that are provided with such solutions are maintained by a team of developers tasked with keeping your data flowing. They will update the connectors you're using every time APIs change, authentication needs adjustment, etc. And with the core system having already been built, your team doesn't have to start from scratch.
These tools quickly pay for themselves.
Nonetheless, organizations often run into instances where a connector isn’t available for a specific source. In these situations, it will be necessary to construct custom jobs that extract data from an API/source and write to a target.

The Future of Data Ingestion
As data ingestion tooling continues to improve, the future of data ingestion looks further automated. Recently, many software companies have released products that improve the ease of creating the custom REST API connections that are eventually required. Further automating these processes, along with the continued development of existing connectors, means that data engineering resources can be focused on how best to store and transform data for analysis.
Recently there has been a movement towards open source for data ingestion tools. Several organizations have released open-source frameworks that allow more advanced data teams to host and deploy their own transformations, free of cost.
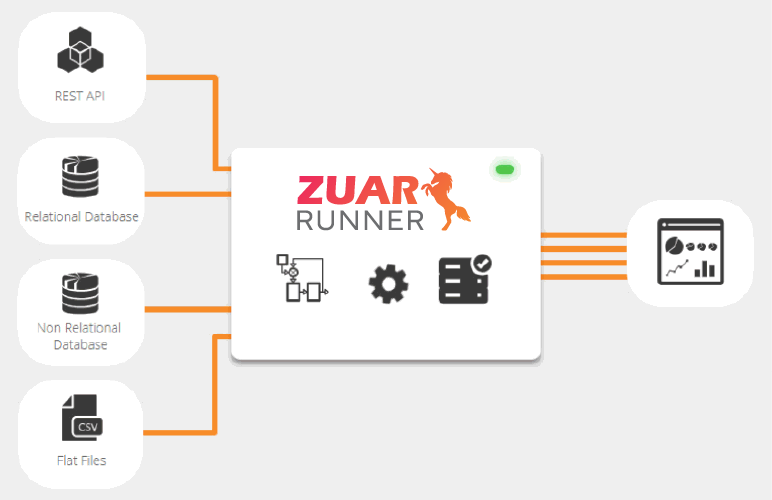
Still, a managed solution like Zuar’s ELT platform Runner affords the greatest amount of time and cost savings. Being an end-to-end solution, Runner can automate every stage of the data pipeline, from ingestion to storage and visualization.
The elimination of management and maintenance in the data space means more time to focus on what matters—delivering insight and value with data. Reach out to Zuar today to understand how you can make the most of your data: