
This article discusses the advantages and disadvantages of ETL vs. ELT for creating a data strategy. At Zuar, we advocated using ELT instead of the more traditional ETL due to the ease of eliminating errors and auditing data with ELT. It does not require data staging because the loading phase begins immediately, and its versatility makes it a modern approach that exceeds the capabilities of ETL.
What is ETL?
Extract-Transform-Load (ETL) is the most common process for building a performant data model out of differing data sources, and has been the main building block for data strategy for almost 50 years. Data is taken from one or more source data systems, merged and converted to a central model, then written to a final data store. The target data store is generally just referred to as a ‘database’ but may be a data warehouse, data mart, data lake or any other system where the resulting data can be efficiently queried.
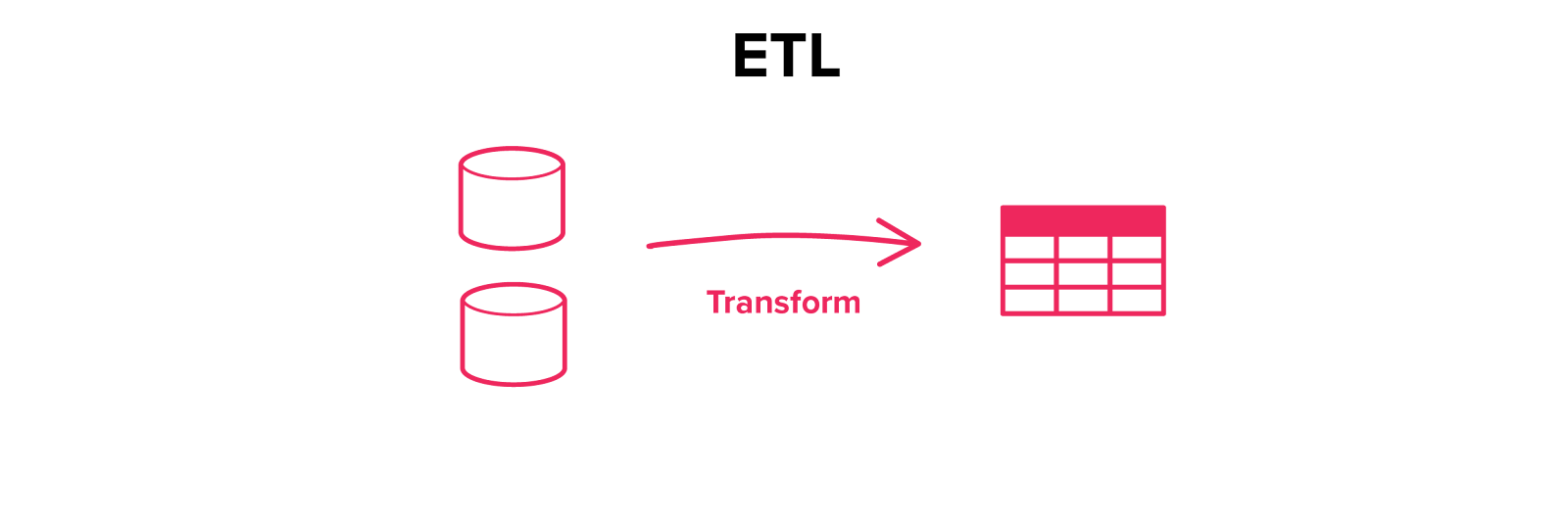
The resulting data model from an ETL process designed to be efficiently queried, with a structure often very unlike that of the source systems. These data models were designed to answer a fixed set of queries instead of the more ad-hoc queries often used today.
Many implementations add additional steps to the ETL process – for example, cataloging or validation of the data – but the overall process continues to be known by ETL. The process of creating a data model, by any method, is frequently referred to as a pipeline.
ETL has been around for a long time, dating back to the 1970s – nearly as long as the concept of a database itself. The ETL process being this old means it was designed for radically different computer resources than are available today. Memory and storage were far more limited – and far more expensive – than those resources are today.
ETL was designed for efficient use of memory and storage at the cost of overall complexity. Transforms of the data were done on a record by record basis before being stored in the final model meaning that a user could only see any of the data once the final model was built. Failures of the process are time consuming to diagnose and fix.
Today storage is comparably cheap – especially cold storage, where the data is not being actively used. Extract-Load-Transform (ELT) trades storage and memory for simplicity.
What is ELT?
ELT brings all source data into a central data store – either the target database or a staging system – and then performs a set of simple transforms keeping the result at each stage until a final data model is achieved. An example of an ELT-based data pipeline solution is Zuar Runner.
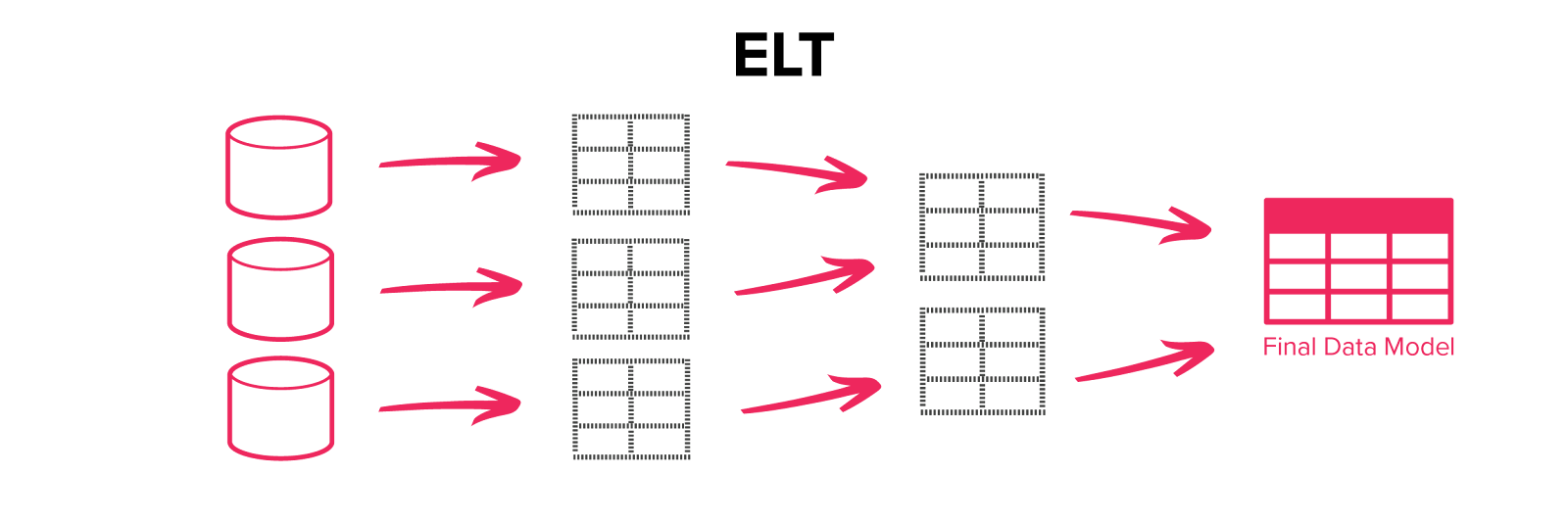
In an ELT process, the steps are not just reordered but the fundamental concept is changed – the results of each transform are kept so that the entire process is auditable. When something goes wrong, having the results of every transform – including a copy of the original source data – allows the problem to be quickly diagnosed and fixed. The picture of ELT may seem to make ELT more complicated than ETL, but in practice, it’s far easier to see what’s happening at each stage of the process.
ELT also allows additional data models to be easily added. In a traditional ETL process, creating another data model required an entirely different ETL pipeline. With ELT, a new data model can be created as a branch of an existing ELT pipeline.
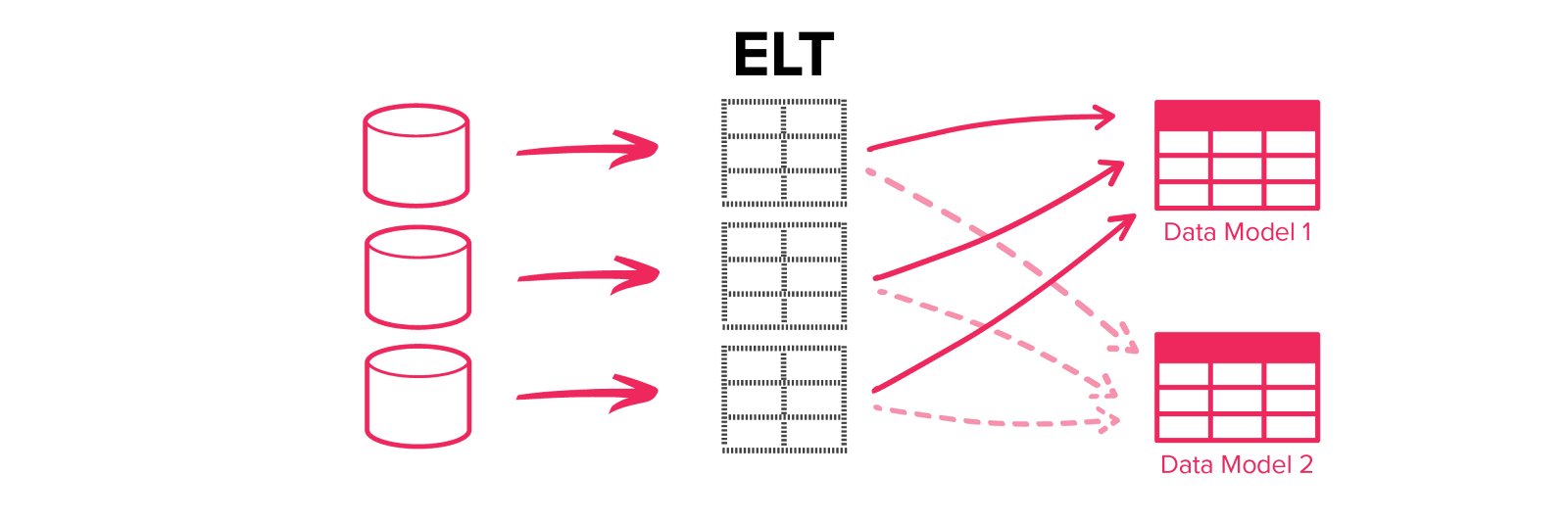
What are the main differences between ETL and ELT?
Both processes for generating working data models have distinct pros and cons that we will discuss. However, it is important to highlight key differences between ETL and ELT because depending on the vision you have for your individual pipeline, one protocol may be preferred over the other.
- ETL has an intermediary staging where transformations take place, while ELT allows for transformation within the data pool that has been extracted and placed in the warehouse.
- ETL’s transformation step generally ensures greater security as the data is transformed and ideally de-identified or encrypted prior to transfer into the data warehouse
- ELT lacks a transformation step prior to placing data into the repository, a potential security concern if there are areas in the pipeline where hackers can easily penetrate.
- ETL can transform your data in ways that ELT cannot do prior to already creating a data model. This intermediate step within the ETL pipeline allows for more sophisticated modulations to the data before it is housed.
| ETL | ELT | |
| SOURCE DATA | STRUCTURED | UNSTRUCTURED, SEMI-STRUCTURED, STRUCTURED |
| DATA SIZE | SMALL AMOUNTS | LARGE AMOUNTS |
| STORAGE TYPE | ON-PREMISE / CLOUD | CLOUD |
| LATENCY | HIGH | LOW |
| FLEXIBILITY | LOW | HIGH |
| SCALABILITY | LOW | HIGH |
| MAINTENANCE | CONTINUOUS | LOW MAINTENANCE |
| COMPLIANCE | EASY | COMPLEX |
| STORAGE REQUIREMENT | LOW | HIGH |
| IMPLEMENTATION COMPLEXITY | EASY | HARD |
| DATA LAKE | UNSUPPORTED | SUPPORTED |
| COST | HIGH | LOW |
| HARDWARE REQUIRED | YES | NO / CLOUD |
Pros and Cons of ETL
What are the pros of ETL?
- Efficient use of system resources. It requires less storage space and processes structured data with minimal resource usage.
- Proven history of use. ETL has been in use for a long time, making it ideal for legacy data.
- Many tools are designed for this process.
What are the cons of ETL?
- More difficult to debug and fix errors. Because ETL chooses data early in advance, it is difficult to debug errors later on in the process. The rigidity of ETL makes it difficult to use in later stages.
- Process changes are notoriously slow to implement. While one might argue that ETL has been tested by time, it’s also true that it can feel outdated now. It only maintains efficiency when using the rigid structure of old data formats.
Pros and Cons of ELT
What are the pros of ELT?
- Entire process can be easily audited. ELT retains raw data making it easy to review each stage of the data pipeline and diagnosing a problem is easier when the results of each step are available.
- Error are easier to fix. The process can be easily restarted at the last successful step after errors are fixed without having to run the entire process from the beginning.
- Quickly extensible. Using raw data enables ELT to be highly flexible. This, combined with the fact that data is readily available, makes development easier.
What are the cons of ELT?
- More system resources required. There are more systems required to store ELT data, but the benefits outweigh the costs if flexibility and expanded capabilities are what you desire.
- May be slower due to additional writes. ELT might be slower due to persisting each step of the process.

How do ETL and ELT handle data lakes and data warehouses?
An ETL strategy vs an ELT strategy are usually designed with the data quality in mind; how clean does the data have to look prior to modeling, for example. However, another factor to consider when running and ETL vs. ELT processing pipeline is whether or not you are dealing with a data lake or a data warehouse.
Data lakes are composites of raw data points that are massive in amount, and vary in type; operations that choose to use data lakes are most likely getting data from multiple sources and pipelines, so consolidating them can be a challenge. A data warehouse is a more traditional framework where it acts a repository for structured data that has a clear end game in sight. Operations that use warehouses tend to have fewer data types, or have separate processing pipelines and repositories across all data collection sources entirely.
Depending on which you are dealing with, ETL vs ELT is something you have to consider. ELT is amendable and easy to implement changes within, so it’s usually a better choice when working with data lakes. ETL has more structure in its pipeline, and the transformations (depending on the complexity of the script) may be harder to change depending on the data type. Thus, ETL is sometimes a better choice when it comes to data warehouses.
Data lakes are the next big frontier in data science since they are so flexible and a result of improved processing power in hardware and software compared to older protocols. There is no longer a need to be as pragmatic about a processing pipeline as before, so naturally, ELT and data lakes are becoming more common and possible.
Choosing a data strategy suitable for an organization is predicated on its needs and the resources available. But if one is looking for a methodology that provides not only immediate results but a foundation for a strategy that will grow with the organization, it’s hard to go wrong with ELT. That’s partly because it’s highly efficient; it only needs to load once and speed does not depend on data size. It’s low-maintenance, scalable, and while ELT requires a little bit more skill, increases efficiency and productivity in the long run because it allows you to work with raw data.
What's for sure, however, is that all organizations, both large and small, have a crucial need for quality and practical data processing tools. If you are interested in finding out how Zuar can help you with your data processing needs, talk with our team to find out more.
Transport, warehouse, transform, model, report & monitor: learn how Runner, Zuar's ELT solution, gets data flowing from hundreds of potential sources into a single destination for analytics.


