
Data Extraction Definition
Data extraction is a term used to describe the process of retrieving data from a source for further processing or storage. With the proliferation of the cloud-native data warehouse, a mastery of data extraction is a prerequisite for building a data-driven organization.
A successful data stack is built on clean, reliable data— hinging on proper extraction from the right sources.
Luckily, data extraction tooling and documentation has blossomed with the growth of the data space in the past decade. Today, more resources than ever are available to help your team pick the right patterns and data extraction tools.
Key Takeaways
- As the 'E' in 'ETL,' data extraction retrieves data from sources for further processing or storage, enabling data-driven decision-making.
- Though it can pose challenges, data extraction provides benefits like efficiency, competitive advantage, and scalability.
- Tools like scripts, APIs, and ETL/ELT software automate the data extraction process.

The Modern Data Stack
The modern data stack (MDS) is a term used to describe a series of tools for data integration. These tools include: a managed data pipeline, a columnar data warehouse (or lake), a data transformation tool, and a business intelligence (BI) platform.
The differentiating factor, or what makes the stack “modern,” is that these tools are cloud-hosted and require (relatively) little technical configuration by the user. Cloud-native technology and low technical configuration enable accessibility and scalability to meet a growing company’s data needs.
These concepts are relatively new in the data space, having exploded in the last decade with the advent of warehouses like Redshift, BigQuery, and Snowflake.
With a growing adoption of the MDS, the need for cloud-native, low-code data extraction tools has mushroomed. Data extraction is a pattern present not only in legacy data systems, but also in the MDS—it’s the first step in ETL/ELT!

Data Extraction and ETL
Extract-Load-Transform (ELT) is a term used to describe the process of pulling data from a source system, loading it to a target, and performing mutations with the ultimate goal of extracting business value. The steps of an ELT data pipeline are:
- Extract: data is pulled from target systems via queries, change data capture (CDC), API calls, or other means and moved to a staging area or cloud storage system.
- Load: original and/or converted data are loaded into a target system. This might entail writing to a file, creating appropriate schemas and tables, or overwriting existing data as part of a job.
- Transform: loaded data is transformed, combined and processed into a consumable product. This includes possible conversion for writing to a target data warehouse or lake.
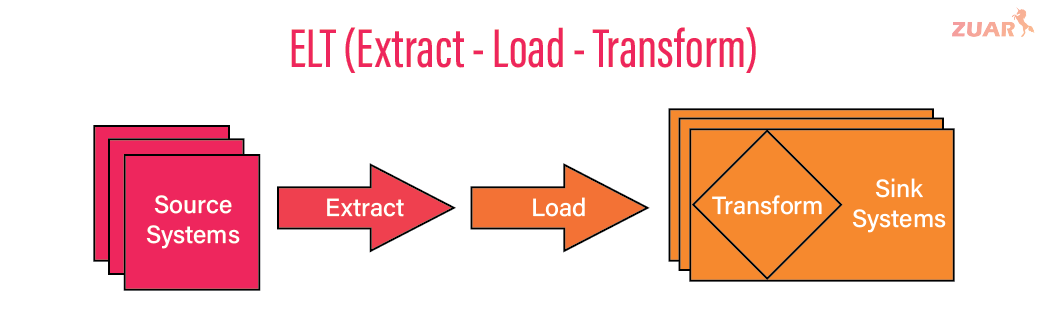
Implementations of the MDS are designed to streamline the ELT process and reduce reliance on development resources, while treating data infrastructure as code (versioning, development environments, etc.).
As cloud storage and compute technologies have evolved, so have data processes. ELT is no exception. Today, there is a vast (overwhelmingly so) selection of tools and architectures to enable modern data reporting.

The Data Extraction Process
In the modern data stack, extraction is usually handled through data integration tools (such as Zuar's ELT solution Runner) or data engineering jobs to interface with source systems.
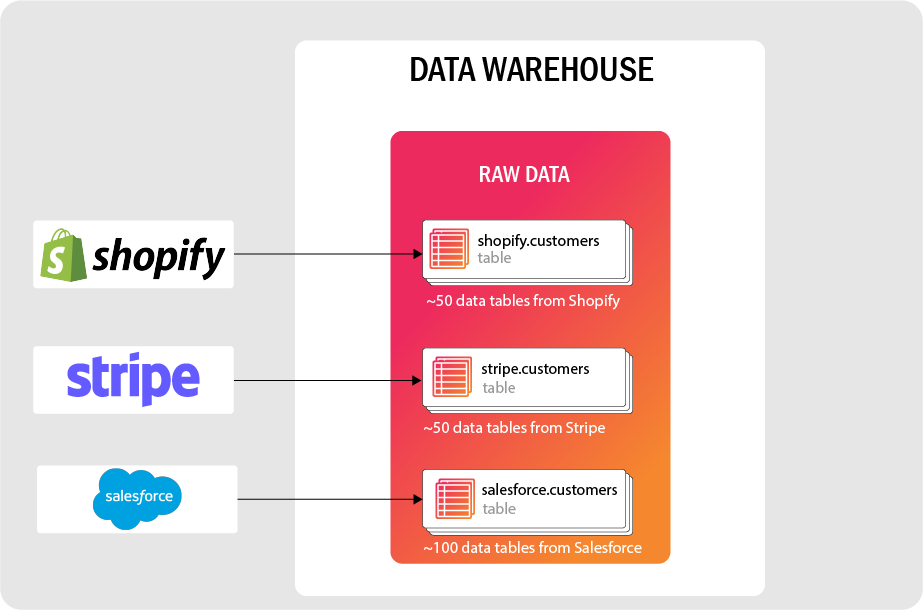
Additionally, there are two types of data that may be extracted: structured and semi-structured. In the extraction process, this data can either be fully loaded to a destination or incrementally loaded.
We’ll walk through these characteristics of data extraction to provide a holistic view of data extraction in the modern data stack.
Extraction Data
Data is most commonly extracted in either structured or semi-structured form, while structured data is generally easier to ingest, most data is not perfectly structured.
Structured Data
Structured data is strictly formatted and typically organized into rows and columns. It can easily be imported to a relational database system and queried. A good example of structured data is a CSV or spreadsheet with consistent columns and rows.
Semi-Structured Data
Semi-structured data has some structure, but it is not as rigid as what may be found in a database. Usually, there exists metadata that may be used to search hierarchies within the data. Examples of semi-structured data include JSON, Avro, and XML.

Types of Data Extraction
Extracted data can be loaded in several ways. Two of the most common are full loads and incremental loads.
Full Load
With a full load, target data is overwritten completely on every extraction job. This pattern is common in systems where the extracted data is very small or flat. In some instances, a full load might be transformed using change data capture (CDC) to log data changes.
Incremental Load
In an incremental load, only data that is new or changed is loaded into the target. Incremental loading has the advantage of being quicker and more lightweight than full loads, since a much smaller volume of data is being extracted.
This comes with a tradeoff: the logic for incrementally loading data is more complex. In some cases, incremental logic can be very dense and difficult to parse. Luckily, many ingestion and transformation tools are making incremental logic more accessible and easy to replicate.

Benefits of Data Extraction
Data extraction offers numerous benefits across various industries, enhancing efficiency, accuracy, and decision-making processes. Here are some of the key advantages:
- Time and Cost Efficiency - Automating the process of data extraction can significantly reduce the time and labor costs associated with manual data entry. This allows businesses to allocate resources more effectively, focusing on analysis and decision-making rather than data collection.
- Accuracy and Reliability - Automated tools can extract data with high accuracy, minimizing human errors that can occur with manual processes. This leads to more reliable data sets for analysis and reporting.
- Enhanced Decision Making - By providing timely and accurate data, data extraction helps organizations make informed decisions. Access to real-time data can be critical for operations, financial management, and strategic planning.
- Improved Data Accessibility and Sharing - A data extraction tool can consolidate information from various sources into a single, accessible format. This makes it easier for teams and departments to share and collaborate on data, leading to more cohesive and aligned strategies.
- Scalability - Automated data extraction systems can easily scale to handle increased volumes of data or additional data sources. This scalability ensures that businesses can continue to effectively manage data as they grow.
- Competitive Advantage - Access to and the ability to quickly analyze data can provide a competitive edge. Organizations can identify market trends, customer preferences, and potential risks faster than competitors, allowing for quicker responses to market changes.
Overall, data extraction is a powerful tool for modern businesses, enabling them to process vast amounts of information efficiently, make evidence-based decisions, and maintain competitiveness in a data-driven world.

Common Issues With Data Extraction
Addressing data extraction challenges is crucial for organizations to ensure the efficiency and reliability of their data extraction processes. Here are some common issues encountered in data extraction:
- Data Quality and Consistency - One of the biggest challenges is ensuring the quality and consistency of the extracted data. Inconsistencies in data format, structure, or content across different sources can lead to inaccuracies and require significant effort to clean and standardize.
- Complex Data Structures - Data sources with complex or unstructured formats, such as PDFs, images, or web pages, can be difficult to extract accurately with automated tools. This complexity can increase processing time and the risk of errors.
- Integration Issues - Integrating the extracted data into existing systems or workflows can be challenging, especially if the systems are not designed to handle the format or volume of the extracted data. This can lead to bottlenecks in data processing and utilization.
- Data Security and Privacy - Ensuring the security and privacy of extracted data, especially sensitive or personal information, is crucial. There's a risk of data breaches or non-compliance with regulations like GDPR or HIPAA if data extraction tools do not have adequate security measures.
- Maintenance and Upkeep - Data extraction tools and processes require regular maintenance to accommodate changes in data sources, formats, and extraction logic. This ongoing upkeep can be resource-intensive.
- Costs - While data extraction can save costs in the long term, the initial setup, including the purchase of tools and training of personnel, can be expensive. Additionally, there may be ongoing costs associated with software licenses, updates, and maintenance.
Addressing these issues typically requires a combination of careful planning, selection of the right tools and technologies, ongoing maintenance and monitoring of data quality, and adherence to best practices in data management and security.

Data Extraction Tools
After inspecting the data source and determining a loading pattern, the data practitioner must choose a data extractor tool to pull data. We’ll discuss the difference between custom-built solutions and off-the-shelf data loaders.
Custom API Connectors
The oldest and most prevalent connection involves directly interfacing with a target API, scraping a data source, or otherwise writing a script to interface with data.
While this approach has the advantage of working with almost every source imaginable, it’s often quite time-intensive, prone to failure (as data sources change), and difficult to implement.
These solutions require extensive resources to host, test, and execute. With the proliferation of data ingestion tools, many are turning to extract-load tools for the bulk of their connections.
Extract-Load Tools
Data extraction and loading tools, like Zuar Runner, eliminate the need for many custom connections through pre-built connectors. These connectors are constructed by teams of engineers to specifically move data between a source and target.
For example, one might implement a Salesforce to Redshift connector that easily connects the two systems.
Connectors can save a tremendous amount of time and resources, since they're typically implemented in hours, compared to days or weeks for a custom connection.
Additionally, since they’re backed by for-profit organizations, connectors are typically updated in a timely manner (often before data changes take place).
Most turnkey solutions of this sort require payment. Nonetheless, data teams often find that some implementation of these tools provides a net benefit, all costs considered. Zuar Runner comes with a multitude of pre-built connectors; you can see the full list here:


Implementing Data Extraction
Gathering data from external sources is essential to enrich the value of internal data and enable data-driven organizations. Clean data forms the base of a well-built data stack, and data extraction is the first step to building that base.
Our team at Zuar is well-versed in data extraction, and we can help guide you through each step of the process: from extraction to visualization and beyond.
Zuar's end-to-end data pipeline solution, Runner can extract your data from a multitude of sources, combine/transform/model it, and transport it to the data warehouse of your choosing. You can jumpstart the process by scheduling a free data strategy assessment with one of our data experts:

