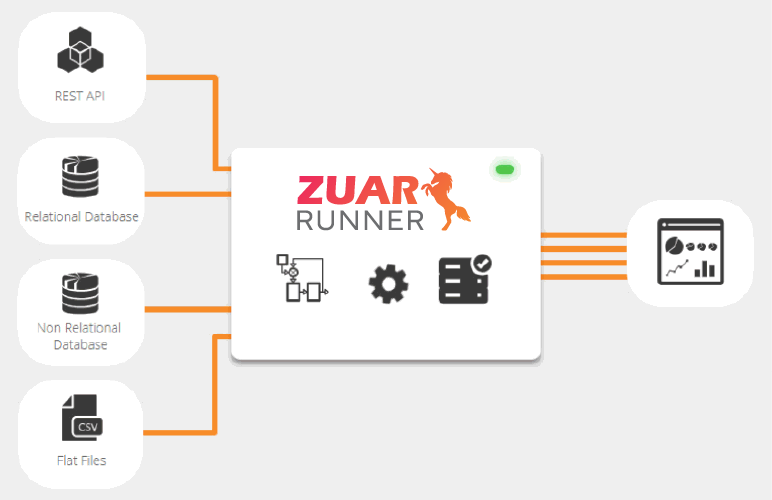
Data flow from one location to another is a critical operation in the modern world's data-driven businesses. Many companies collect data for analysis.
However, the data flow is not always smooth, and it can be slowed down in the transportation from one area to the other. This dataset can become corrupted, cause latency, or generate duplicates.
With a data pipeline, the software enables a smooth flow of information. It automates the process of extracting, validating, and loading the data for analysis. This system eliminates errors and combats latency.
Along with that, the data pipeline can process several streams of data at one time. Effective data pipelines are critical for data-driven enterprises.

Definition of a Data Pipeline
A data pipeline uses actions to interpret raw data from several sources and move it to another location for analysis. These pipelines include filtering features that help protect the data against any failure. Many businesses use a data pipeline to integrate information from multiple sources to gain a competitive advantage.
Types of Data Pipelines
The most common types of data pipelines include:
Batch
When companies need to move a large amount of data regularly, they often choose a batch processing system. With a batch data pipeline, this data is not transferred in real-time. Some companies will use this system to integrate their marketing data into a larger system for analysis later.
Real-Time
In a real-time data pipeline, the data is processed almost instantly. This system is useful when a company needs to process data from a streaming location, such as a connected telemetry or financial market.
Cloud
Data from AWS buckets are optimized to work with cloud-based data. These tools can be hosted in the cloud, and they allow a company to save money on resources and infrastructure. The company relies on the cloud provider’s expertise to host the data pipeline and collect the information.
Open-Source
A low-cost alternative to a data pipeline is known as an open-source option. These tools are cheaper than those commercial products, but you need some expertise to use the system. Since the technology is available to the public for free, other users can modify it.
Data Lake vs. Data Warehouse
Data lakes and data warehouses store various types of big data. However, these are two separate terms. A data lake contains a large pool of raw data where the user has not defined the use of this data. And a data warehouse is a storage space for filtered data designated for a specific purpose.
Many users often confused these types of data storage systems. The only similarity between these locations is the purpose of storing data. Data lakes and data warehouses serve different purposes for different companies. What may work for one business might not be the right fit for another.

Want an efficient data solution for your company? Work with Zuar today!
Types of Data in a Data Pipeline
Businesses can store different types of data in a data pipeline, such as:
Structured vs. Unstructured Data
There are two types of data in a pipeline: structured and unstructured data. Structured data is information that adheres to a predefined manner or model. This type of data can be quickly analyzed.
Unstructured data is gathered information that is not organized in a predefined way or model. This type of unstructured data is very text-heavy as it contains facts, dates, and numbers. With its irregularities, this information is difficult to understand compared to data in a fielded database.
Raw Data
Raw data is information that has not been processed for any particular purpose. This data is also known as primary data, and it can include figures, numbers, and readings. The raw data is collected from various sources and moved to a location for analysis or storage.
Processed Data
Processed data comes from collected raw data. System processes convert the raw data into a format for easier visualization or analysis. These processes can also clean and transform the processed data into the desired location.
Cooked Data
Cooked data is another type of raw data that has gone through the processing system. During processing, the raw data has been extracted and organized. In some cases, it has been analyzed and stored for future use.

How to Build a Data Pipeline
A data pipeline's functionality serves to collect information, but it is also a method to store, access, and analyze the data according to the user's configuration. If you want to build data pipelines, it should store and compress any cumulative data. You can build your own data pipeline to audit and analyze the information.
Parts of a Data Pipeline
There are several parts of a data pipeline:
- The origin, or point of data, is the final point of the data called a definition.
- The movement of that data is called the dataflow.
- One of the data collection approaches is referred to as ETL (extract, transform, and load). This is where different storage areas preserve the data.
Once the raw data has been collected, it can be processed and analyzed.
Optimizing Data Pipeline Design
For an optimized data pipeline, the system must be free of any latency. These pipelines also must be able to properly collect the data and deliver it to the predetermined destination.
After the data is collected, it can be stored or analyzed for immediate use. Optimizing the design will help to move the data quickly without any bottlenecks in the system.
Examples of Efficient Data Pipeline Architecture
There are two examples of data pipeline architectures: batch processing and streaming data processing.
Batch processing involves transporting large chunks of data that have been stored over a period of time. This type of architecture is excellent for those instances where the data needs to be processed later.
Streaming data pipelines can process data in real-time. Data is entered and analyzed within seconds, and it is commonly found in point of sale systems.
Data Pipeline vs. ETL
Many people use the terms data pipeline and ETL interchangeably. As previously stated, ETL stands for extract, transform, and load. This is where large batches of data are moved at a specific time in the system.
A data pipeline is a broad term that covers the ETL process. It refers to moving data from one location to another. However, with a data pipeline, the information is transformed and processed in real-time.

Data Pipeline Usage
A data pipeline is an essential tool to help collect information for businesses. This raw data can be collected to analyze user's habits and other information. With a data pipeline, the information is efficiently stored at a location for immediate or future analysis.
Storing Data
Data can be stored at different stages in the data pipeline. These storage options will depend on several different factors, such as the frequency of the data and the volume of the queries.
When the data is needed, the information is recalled and moved to another location for analysis. These storage areas are often found on-site at the business or stored in the cloud.
Metadata
Metadata is often called "data that provides information about other data." There are several metadata types in a data pipeline, including:
- Descriptive
- Structural
- Reference
- Statistical
All this metadata can be analyzed in a data pipeline.
App Embeds
App embeds can help to collect data from customers or clients. As the individual uses the app, data is collected from their activity. This data is collected and processed through the data pipeline. With an efficient data pipeline, the information is analyzed for real-time results or stored for later use.
Data Pipelines are Essential for Efficiency When Collecting Raw Data
A data pipeline is an efficient way to collect raw data from several sources and move it to a location for analysis or storage. This data pipeline process cuts down on lost information and other problems. Your business can benefit from the use of a data pipeline in your company.
Designing and maintaining the optimal data pipeline for your company can be daunting. Connect with Zuar for a free Data Strategy Assessment.
Learn more about Zuar's ELT pipeline solution, Runner: