Introduction to Data Integration Processes
For several decades, data practitioners have used an integration strategy known as an ETL (extract, transform, load) to capture data from multiple sources and process it into a usable asset for business intelligence.
As data processing technology has evolved, so too have the tools and methods for extracting value from data. New approaches leveraging cheap cloud storage and managed, auto-scaling computing have emerged, bringing flexibility and power to data pipelines.
In this article, we’ll compare traditional ETL to ELT (extract, load, transform). We’ll also introduce a third concept, Reverse ETL, and explain how it differs from a traditional pipeline and where it fits into the modern data stack.
These ETL methodologies are critical for organizations looking to gain greater insight from their data and eliminate data silos.
Key Takeaways
- ETL is a traditional data integration strategy that extracts, transforms, and loads data into target systems.
- ELT first loads data and then transforms it afterward to leverage cheap cloud storage and computing.
- Reverse ETL eliminates data silos by copying cleaned data back out to business systems, powering workflows beyond analytics.

What Is ETL?
Since databases have existed for over 50 years, it’s no surprise that techniques for managing their contents have too.
ETL was a process that originated in a time of on-prem servers and hardware-based solutions for managing data from multiple sources, pairing it down to eliminate the high cost of storage, and organizing it to enable meaningful insights for business analysts writing SQL.
Much has changed, but the core tenets of ETL remain the same: businesses pull messy data from an array of providers. That data must be cleaned, transformed, and stored in a data warehouse or related, then analyzed and displayed in a manner that drives insight.
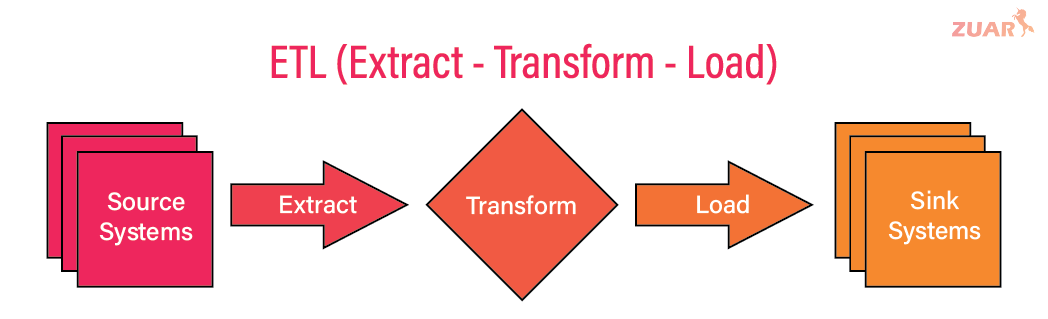
An ETL data pipeline consists of the following:
- Extract: data is pulled from target systems via queries, change data capture (CDC), API calls, or other means and moved to a staging area.
- Transform: staged data is transformed, combined, and processed into a consumable product. This includes possible conversion for writing to a target data warehouse or lake.
- Load: original and/or converted data are loaded into a target system. This might entail writing to a file, creating appropriate schemas and tables, or overwriting existing data as part of a job.
The most impactful changes in data infrastructure have arisen on the storage and processing front, with the greatest being the rise of the Cloud Data Warehouse. Today, companies rarely store their data on-site, manage their own hardware, or worry about scaling their operations.
Instead, solutions are hosted in the Cloud through providers like Amazon, Google, or Microsoft.
Cloud-hosted warehouses drastically reduce the friction to standing up a functioning data stack— they’re entirely managed by the provider: storage and computation can scale to practically infinite levels, accommodating increased demands for processing and storage.
Businesses no longer need to worry about hardware management, software installation, or other physical demands to meet data goals. As such, the way we think about data extraction and loading has shifted: enter, ELT.
ETL Use Cases
One use case for ETL is data migration, where ETL processes are employed to transfer data from one system or location to another.
This could involve moving data from an on-premises system to the cloud or consolidating data from multiple sources into a centralized data warehouse for further analysis and reporting.
ETL tools and processes help ensure that data is extracted from the source systems, transformed to meet the target system's requirements, and loaded efficiently and accurately into the destination system.
By utilizing ETL, organizations can streamline the migration process and maintain data integrity during the transition.

What Is ELT?
ELT is also a data integration process enabling data extraction from various sources. It’s very similar to the ETL, but the transform and load stages are switched.
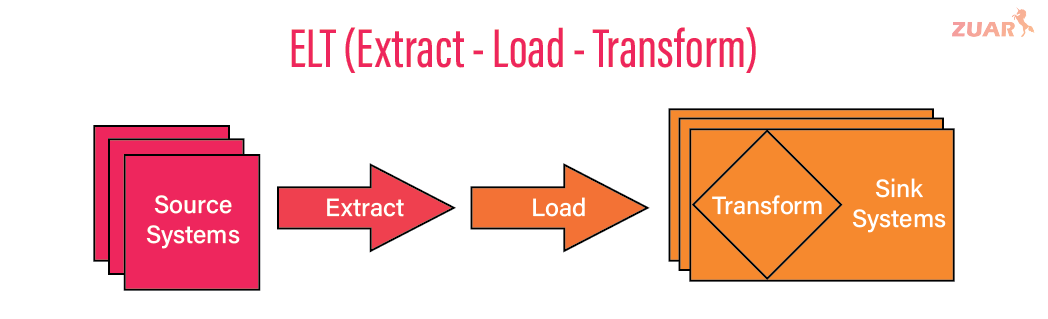
In an ELT, all data is first loaded into a target system, where it is later transformed and enriched. Transformations are still necessary for reporting and synthesis. This is where popular tools like DBT and Dataform come in.
Such tools provide a versioned and programmatic way to transform loaded data, while leaving original sources as they were. According to Craig Mullins, President & Principal Consultant at Mullins Consulting, Inc.:
Traditional ETL works well when processing smaller amounts of data requiring complicated transformation, but ELT can be more appropriate for larger amounts of unstructured and structured data and when raw data is required for the data warehouse.
Since the 'loaded' data is not altered, transformations can be edited retroactively. In a traditional ETL, data is transformed and mutated before being loaded, so it’s not possible (or at the least very difficult) to re-run transformations on previously extracted data.
Now, data transformations can be continuously revised and edited without losing any historical information. This enables tremendous flexibility in data processing and shifts the way organizations think about data capture!
It’s cloud data warehouses that enabled this shift. As cloud storage has matured, costs for processing and storage have continued to fall. Now, storage is incredibly cheap and scalable. So, it makes sense to keep everything and worry about optimal transformations later.
Additionally, there can now be complete separation between storage and compute, of which both scale dynamically in cloud environments. Increasing degrees of freedom allow data teams and businesses to fine-tune cloud products and optimize their behavior to save on cost, while getting a huge bang for their buck.
According to Zuar CEO Whitney Myers:
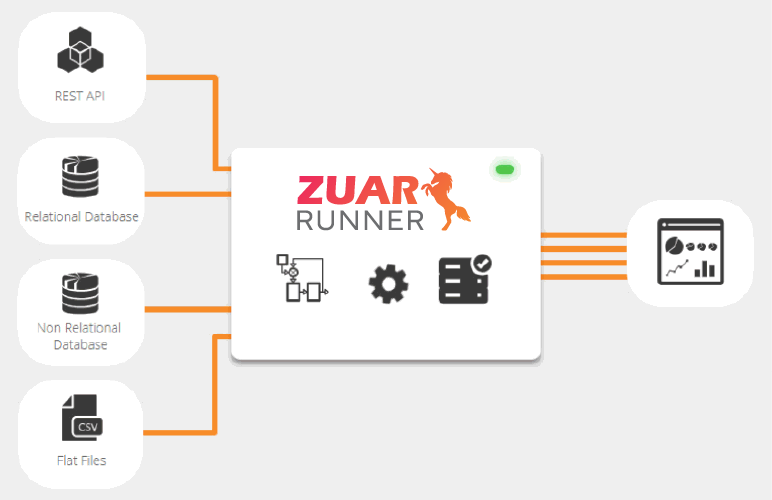
The ELT approach provides a solid foundation that can be easily iterated upon as both business needs and corresponding technologies change. Runner, Zuar’s ELT and data staging solution, helps customers quickly access important data that is ready for analysis, while transforming data coming from disparate sources into a single, easy-to-visualize set of data tables. Zuar Runner enables customers to access critical info in minutes/hours, instead of after weeks and months of planning.
For more information on the differences and pros/cons of ETL vs. ELT, check out these other Zuar articles:
 Matthew R Laue
Matthew R Laue Team Zuar
Team Zuar
ELT Use Cases
One use case for ELT is data warehousing and big data analytics. In this scenario, ELT allows organizations to extract data from various sources and load it directly into a data lake or data warehouse without prior transformation.
The transformation step is then performed at the target system, enabling organizations to take advantage of the immense processing power and scalability of modern big data platforms like Hadoop or Apache Spark.
ELT is particularly useful when dealing with large volumes of data or when the transformation requirements are complex and require advanced analytics or machine learning algorithms.
By leveraging ELT, organizations can optimize performance, flexibility, and cost-effectiveness in their data analytics processes.

What Is Reverse ETL?
Now that we understand ETL and ELT, we can introduce an even newer concept: Reverse ETL. Reverse ETL differs from the earlier processes in that it’s a tertiary step that occurs after data has been processed. So it does not replace ETL or ELT.
Now, you may be thinking “we just went through all of that trouble to get our data into a data warehouse, why are we attempting to do the reverse?” Well, that’s a valid point.
The answer has to do with the proliferation of data tools, mostly centered around sales, marketing, support, and other business-essential operations.
How Does Reverse ETL Work?
Cleaned data that resides in a warehouse after ETL or ELT is great and highly valuable to an organization, but only in the sense that it can be used for analysis and insight.
This is traditionally done by analysts writing SQL or connecting BI tools like Looker or Tableau, but there are other organizations in a business that need data to make decisions.
Sales teams, for example, might rely on processed data for leads and upsells, but how can they then access this data in popular sales tools, like Salesforce?
Marketing, similarly, might use HubSpot for campaigns, but how can the marketing team put their communications in context for users and ensure relevancy?
That’s where the Reverse ETL comes in. Reverse ETL tools automate the process of copying cleaned data from the warehouse to operational/business systems to power operations, forecasting, and other workflows.
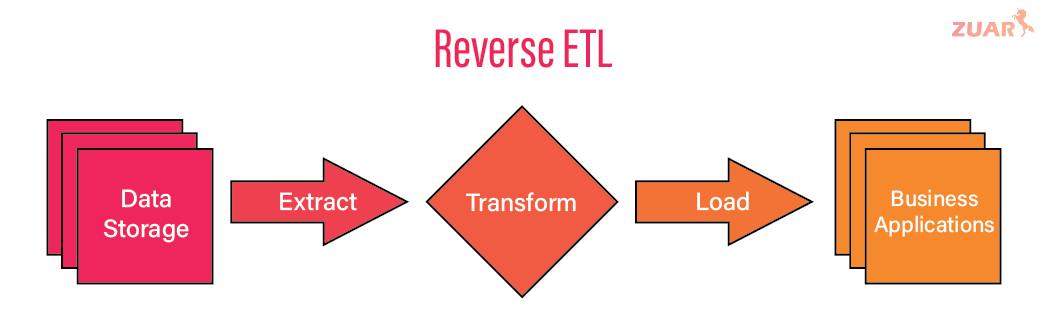
The Reverse ETL is a necessary feature for data teams looking to remove silos and expand access to business insights beyond the analytics team.
With more and more tooling for teams that traditionally live outside the 'data' space, Reverse ETL is a technique for providing context and enrichment to customer/logo relationships on those platforms.
Reverse ETL Use Cases
Typical reverse ETL use cases include powering personalization across various tools in a tech stack, enabling real-time data integration with external systems for operational decision-making, and providing up-to-date data to business applications for better customer engagement and analysis.
By implementing a reverse ETL tool, organizations can enhance data utilization, facilitate seamless data transfer, and derive valuable insights for improved business outcomes.

Tying it All Together
ETL is a data process that’s been around as long as the ubiquitous database. It consists of extracting data from one or many sources, transforming it to suit a business's needs, and loading it to a final destination, whether physical or virtual.
ELT is a new, more modern approach that leverages cheap storage and scalable resources to retain all extracted data and transform it as a final step. Finally, Reverse ETL is an additional step for enriching external systems with cleaned data obtained through ETL/ELT.
With a well-designed combination of ELT + Reverse ETL, businesses may derive greater insight from the data they collect, and share those insights with the entire organization.
Operations-centric teams may leverage cleaned data to drive new sales, provide personalized marketing, or replicate data in modern cloud applications.
These ETL/ELT methodologies are instrumental when it comes to your data integration strategy, but implementing these processes can often be a daunting task.
That's when it helps to turn to the experts. Zuar can assist you with every stage of your data pipeline, from data transportation and warehousing, to workflow automation, to reporting and monitoring.