
In this article we've documented answers to the questions that Zuar frequently gets from the Amazon Redshift users and account admins that we work with on a daily basis.

What storage types does Redshift use?
Amazon Redshift stores data in columnar format. This means data is accessed by column rather than by row. In a typical relational database, records are stored by row:

With row-wise storage, data is written sequentially by row. If a row is large enough, it may take up multiple blocks. If too small, the row will take up less than one block, resulting in an inefficient use of disk space. This type of storage is optimal for solutions frequently reading and writing all values of a record, typically one or a small number of records at a time. As such, row-wise storage is ideal for online transaction processing (OLTP) application data-stores.
Columnar storage, by contrast, stores values by each column into disk blocks.

Using column-wise storage, each data block can be entirely filled. In the example above, one column-wise block holds the same amount of data as three row-wise blocks! This translates directly to I/O operation efficiency. Storage efficiency is even greater in larger datasets. Columnar datastores are extremely efficient for read workloads requiring small sets of columns, like BI or analytics. These datastores are frequently called online analytical processing (OLAP).
For Amazon Redshift, this means efficiency in storage, I/O, and memory.
How do I load data to Redshift from external sources?
Syntax:
COPY table-name
[ column-list ]
FROM data_source
authorization
[ [ FORMAT ] [ AS ] data_format ]
[ parameter [ argument ] [, ... ] ]
This can be used to load files from Amazon EMR, S3, Dynamo or SSH.
How do I insert rows into a table?
Syntax:
INSERT INTO table_name [ ( column [, ...] ) ]
{DEFAULT VALUES |
VALUES ( { expression | DEFAULT } [, ...] )
[, ( { expression | DEFAULT } [, ...] )
[, ...] ] |
query }
For example, to insert an individual row into an existing table, use comma-delimited values corresponding to the column names. Take the following example for a trails table with columns name, city, state, length, difficulty, type:
INSERT INTO hiking_trails VALUES (‘Craggy Gardens’, ‘Barnardsville’, ‘NC’, ‘1.9 miles’, ‘easy’, ‘hiking’);
You can also INSERT from another table:
INSERT INTO trails (SELECT * FROM trails WHERE type=’hiking’)

How do I export to CSV?
Syntax:
UNLOAD ('SELECT * FROM VENUE')
TO [path-to-s3-bucket]
IAMROLE [redshift-iam-role]
CSV;
With the appropriate bucket path and IAM role. UNLOAD accepts a number of arguments, discussed in further detail here.
How do I create a new user?
Syntax:
CREATE USER name [ WITH ]
PASSWORD { 'password' | 'md5hash' | DISABLE }
[ option [ ... ] ]
where 'option' can be:
CREATEDB | NOCREATEDB
CREATEUSER | NOCREATEUSER
SYSLOG ACCESS { RESTRICTED | UNRESTRICTED }
IN GROUP groupname [, ... ]
VALID UNTIL 'abstime'
CONNECTION LIMIT { limit | UNLIMITED }
SESSION TIMEOUT { limit }
A simple example of a user with a password:
CREATE USER newman WITH PASSWORD '@AbC4321!';
Parse JSON in Redshift
How do I check for a valid JSON string or array?
To check for valid, simple JSON strings use:
IS_VALID_JSON(‘string’)
For JSON arrays:
IS_VALID_JSON_ARRAY(‘string’)
How do I extract elements from a JSON array?
To extract a JSON element by position in a JSON Array:
JSON_EXTRACT_ARRAY_ELEMENT_TEXT('json string', pos [, null_if_invalid ])
Example usage:
SELECT JSON_EXTRACT_ARRAY_ELEMENT_TEXT('[111,112,113]', 2);
This selects element two, 113.
To extract a JSON element by key:
JSON_EXTRACT_PATH_TEXT('json_string', 'path_elem' [,'path_elem'[, …] ] [, null_if_invalid ])
Example usage with nested JSON:
SELECT JSON_EXTRACT_PATH_TEXT('{"f2":{"f3":1},"f4":{"f5":99,"f6":"star"}}','f4', 'f6');
This selects the keys f4, then f6 (sequentially), returning “star.”
How do I generate Redshift DDL for existing table?
There are times when it is necessary to recreate a table (e.g. copying a table across clusters). To do that, you can query Redshift to get the DDL for any table with:
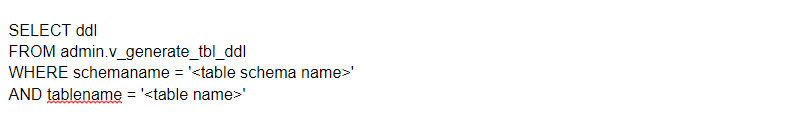
What functions get my redshift system info?
SELECT CURRENT_AWS_ACCOUNT();
SELECT CURRENT_DATABASE();
SELECT CURRENT_NAMESPACE();
SELECT CURRENT_SCHEMA();
SELECT CURRENT_USER();
SELECT CURRENT_USER_ID();
See more Redshift system information functions.
How can I list all users, groups, databases?
SELECT * FROM pg_user;
SELECT * FROM pg_group;
SELECT * FROM pg_database;
How can I troubleshoot loading errors?
Selecting from stl_load_errors provides information about errors during loading, and can be helpful for troubleshooting problematic loads.
SELECT *
FROM stl_load_errors
ORDER BY starttime DESC
LIMIT 100;
How do I get SQL from query_id?
SELECT LISTAGG(text) WITHIN GROUP (ORDER BY sequence) AS sql
FROM STL_QUERYTEXT
WHERE query = …;
What is the best way to assess tables that need to be vacuumed or analyzed?
This query returns tables where greater than 20% of rows are unsorted or statistics are 20% stale.
SELECT "database", "schema", "table", unsorted, stats_off
FROM svv_table_info
WHERE unsorted > 20
OR stats_off > 20
Running VACUUM or ANALYZE on these tables may improve performance by keeping rows sorted and providing the query planner with accurate information.
How do I manipulate Dates in Redshift?
Add dates: this example returns ‘2021-01-31’— 30 days after Jan. 1, 2021.
SELECT DATEADD(day, 30, ‘2021-01-01’)
Subtract dates: this example returns 52— the number of weeks in a calendar year.
SELECT DATEDIFF(week,'2021-01-01','2021-12-31')
Get Date Parts
The following examples extract various elements of dates. Multiple are provided for clarity.
SELECT DATE_PART(minute, '2021-01-01 08:28:01');
This will return ‘28,’ the minute component of the timestamp.
SELECT DATE_PART(w, '2021-06-17 08:28:01');
This will return ‘24,’ the week number of the year.
Alternatively, you could also use EXTRACT, which takes different arguments, but works identically:
SELECT EXTRACT(week from ‘2021-06-17’)
Truncate Timestamp
DATE_PART truncates a timestamp based on the specified part. The example will return ‘2021-09-01,’ the pertinent month.
DATE_TRUNC(‘month’, ‘2021-09-05’)
For more information see Redshift’s date part and timestamp functions.
Check out some of our other database cheat sheets:
How do I combine my Redshift data with other data sources, prepped and ready for analysis?
Analyzing data across your business solutions is simplified with Zuar Runner. You can automate your ELT/ETL processes and have data flowing from hundreds of potential sources, like Redshift, into a single destination. Transport, warehouse, transform, model, report, and monitor: it's all managed by Runner. You can learn more about Runner here.
Other relevant articles:



