What is AWS S3?
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers high scalability, data availability, security, and performance. It provides features to optimize, organize, and configure access to your data to meet organizational requirements.
It is the most fundamental and global Infrastructure as a Service (IaaS) solution provided by Amazon Web Services (AWS).
With its simple web service interface, it is easy to store and retrieve data on Amazon S3 from anywhere on the web. All one needs to do is choose a region (which is a separate geographic area, choose the closest one to you), create an S3 bucket and start storing data.
Amazon S3 automatically creates multiple replicas of your data so that it's never lost.
Key Benefits
- Durability: S3 provides 99.999999999 percent durability. In case of data corruption, multiple copies are maintained to enable regeneration of data. It regularly verifies the integrity of data stored using checksums (e.g., if S3 detects there is any corruption in data, it is immediately repaired with the help of replicated data).
- Availability: S3 offers 99.99% availability of objects.
- Low cost: S3 lets you store data in a range of 'storage classes.' These classes are based on the frequency and urgency for accessing files.
- Scalability: S3 charges you only for what resources you actually use, and there are no hidden fees or overage charges. You can scale your storage resources according to organization’s requirements.
- Resiliency: One of the more impressive characteristics of Amazon S3 is how well it handles failures. It does this in part by automatically storing every object at minimum in three Availability Zones, providing 99.999999999% durability and availability of objects over the course of a year.
- Security: S3 offers an impressive range of access management tools and encryption features that provide top-notch security. It provides both client-side and server-side encryption for data security.
- Flexibility: S3 is ideal for a wide range of uses like data storage, data backup, software delivery, data archiving, disaster recovery, website hosting, mobile applications, IoT devices, and much more.
- Simple Data Transfer: Data transfers on S3 are simple and easy to use.
- Versioning: S3 keeps multiple copies of a file to track the changes over time. This is useful while handling sensitive data.
- Ease of Migration: With Amazon S3 you get multiple cost effective options (rsync, S3 command line interface, and Glacier command line interface) for Cloud Data Migration, making it simple to transfer a large amount of data in or out of Amazon S3. Amazon S3 storage also provides you with the option to import or export data to any physical device or on any network.

Buckets in S3
A bucket is a container for objects stored in Amazon S3. In S3, files are stored in buckets. It is similar to folders on your computer. The unique name of a bucket is useful to identify resources. There are no limits on the number of files you can store in a bucket. Buckets also provide additional features such as version control.
A user creates a bucket and specifies the region in which the bucket is to be deployed. Later, when files are uploaded to the bucket, the user determines the type of S3 storage class to be used for specific objects. After this bucket features are defined such as bucket policy, lifecycle policies, versioning control, etc.

S3 Storage classes
S3 Standard
S3 Standard is the default storage plan. This storage class has excellent performance, durability, and availability. It is the best option when data needs to be accessed frequently.
S3 Infrequent Access (S3-IA)
S3 Infrequent Access offers a lower price for data compared to the standard plan. S3-IA can be used when data is less needed. S3-IA is great for backups and disaster recovery based use cases.
Glacier
Glacier is the least expensive storage option in S3 and is designed for archival storage. Data cannot be fetched from Glacier as fast as compared to Standard or S3-IA, but it is a great option for long-term data archival. In addition to choosing one of these three storage classes, we can also set lifecycle policies in S3 which means files can be scheduled to move automatically to S3-IA or Glacier after a certain period of time.
One Zone-IA Storage Class
It is designed for data that is used infrequently but requires rapid access. Use of S3 One Zone-IA is indicated for infrequently accessed data without high resilience or availability needs, data that can be recreated and backed up on-premise.
Amazon S3 Standard Reduced Redundancy Storage
Suitable for a use case where the data is non-critical and reproduced quickly. Example: Books in the library are non-critical data and can be replaced if lost.
AWS S3 Replication
S3 supports automatic, asynchronous copying of objects across buckets. Objects can be replicated to a single destination bucket or to multiple destination buckets. The destination buckets can be in different AWS Regions or within the same Region as the source bucket.
S3 supports a live replication feature such as Same-Region Replication (SRR) or Cross-Region Replication, replicating objects as and when created.

AWS S3 Command Line Interface (CLI) Commands
Create bucket from CLI
$ aws s3api create-bucket --bucket cdtest-bucket --region us-east-1
{
"Location": "/cdtest-bucket"
}Upload a file to bucket
$ aws s3api put-object –bucket cdtest-bucket –key dir-1/testfile.txt –body testfile.txtDownloading an object
$ aws s3api get-object --bucket cdtest-bucket --key dir-1/testfile.txt download.txt
{
"AcceptRanges": "bytes",
"LastModified": "2022-06-01T02:28:59+00:00",
"ContentLength": 12,
"ETag": "\"07c0431842313cc81b68b1c0ba3ab467\"",
"ContentType": "binary/octet-stream",
"Metadata": {}
}Delete object in S3
$ aws s3api delete-object --bucket cdtest-bucket --key dir-1/testfile.txtList all objects in S3 buckets
$ aws s3api list-objects --bucket cdtest-bucket
{
"Contents": [
{
"Key": "dir-1/testfile1.txt",
"LastModified": "2022-06-01T02:41:16+00:00",
"ETag": "\"1df628533018d9ceac1c5842219a174e\"",
"Size": 28,
"StorageClass": "STANDARD",
"Owner": {
"DisplayName": “<removed>,
"ID": “<removed>”
}
},
{
"Key": "dir-1/testfile2.txt",
"LastModified": "2022-06-01T02:41:23+00:00",
"ETag": "\"1df628533018d9ceac1c5842219a174e\"",
"Size": 28,
"StorageClass": "STANDARD",
"Owner": {
"DisplayName": “<removed>,
"ID": “<removed>”
}
}
]
}Delete bucket with objects
$ aws s3 rb s3://cdtest-bucket --force
delete: s3://cdtest-bucket/dir-1/testfile1.txt
delete: s3://cdtest-bucket/dir-1/testfile2.txt
remove_bucket: cdtest-bucketList all S3 buckets
$ aws s3api list-buckets
{
"Buckets": [],
"Owner": {
"DisplayName": “<removed>,
"ID": “<removed>”
}
}
aws s3api put-object --bucket cdtest-bucket --key dir-1/testfile.txt --body te
stfile.txPresigned URL for sharing private files
$ aws s3 presign s3://cdtest-bucket/dir-1/testfile1.txt
Amazon S3 to Host a Static Website
Let's learn more about AWS S3 via a practical example. Below are a few simple and easy steps to host a static website on S3.
Step 1: Create an S3 bucket
To host a static website on S3 we first need a bucket.
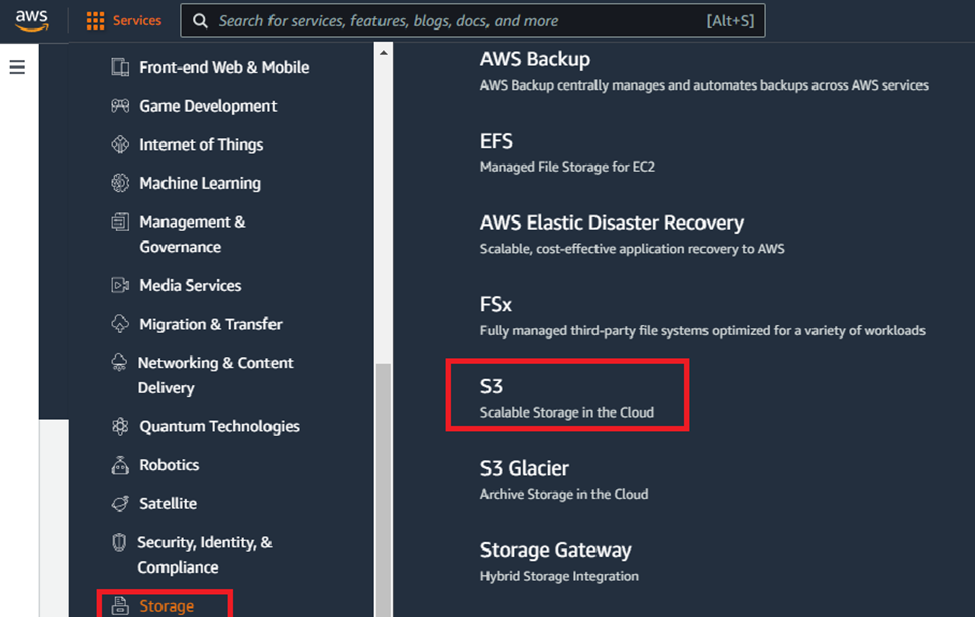
- Login to your AWS account.
- From services, select “S3” from the “storage” section.
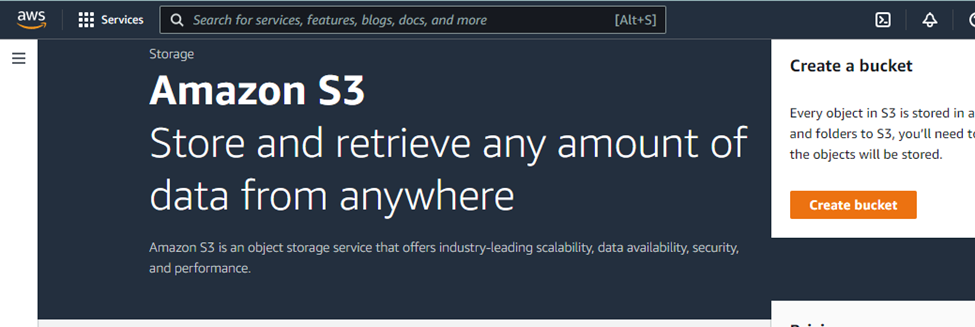
- From S3 dashboard, click on “create bucket”.
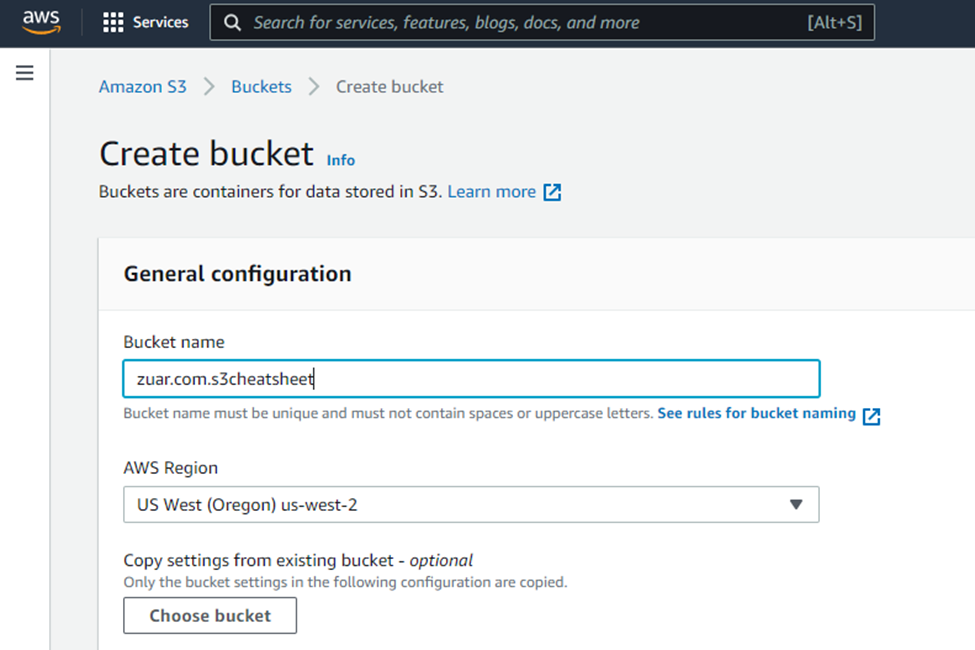
- Choose your preferred AWS region.
- Under Block Public Access settings for this bucket section, uncheck the “Block all public access” checkbox and accept the acknowledgement.
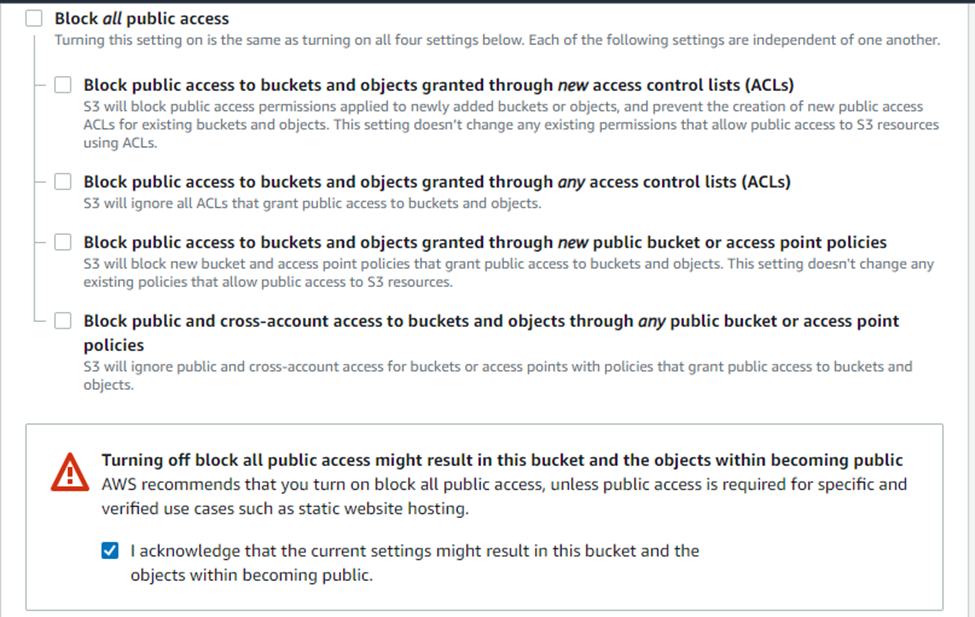
- Click on “Create bucket”
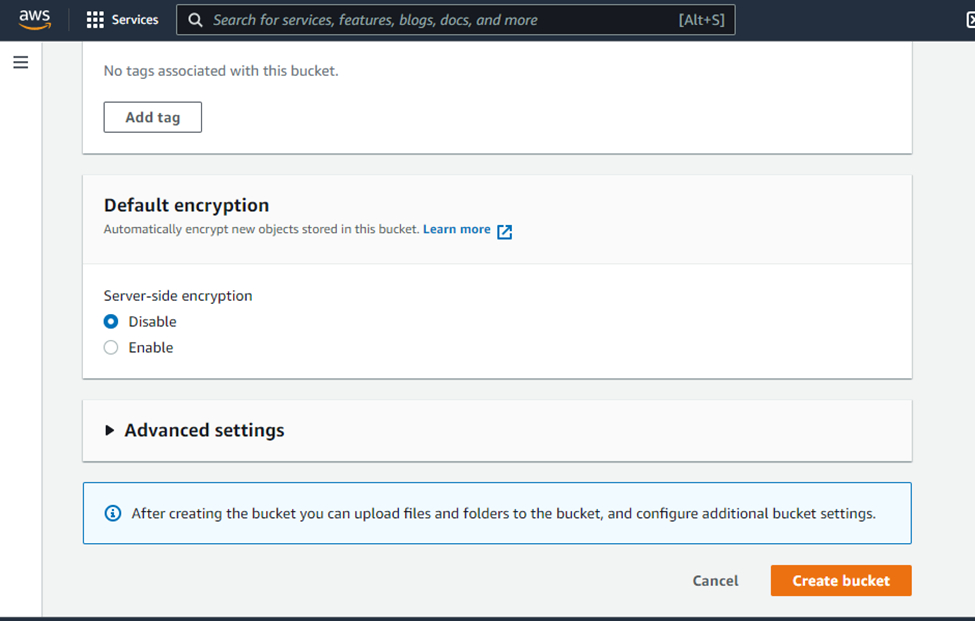
Step 2: Upload web files to S3 bucket
- From the S3 dashboard, click on the name of the bucket you just created.
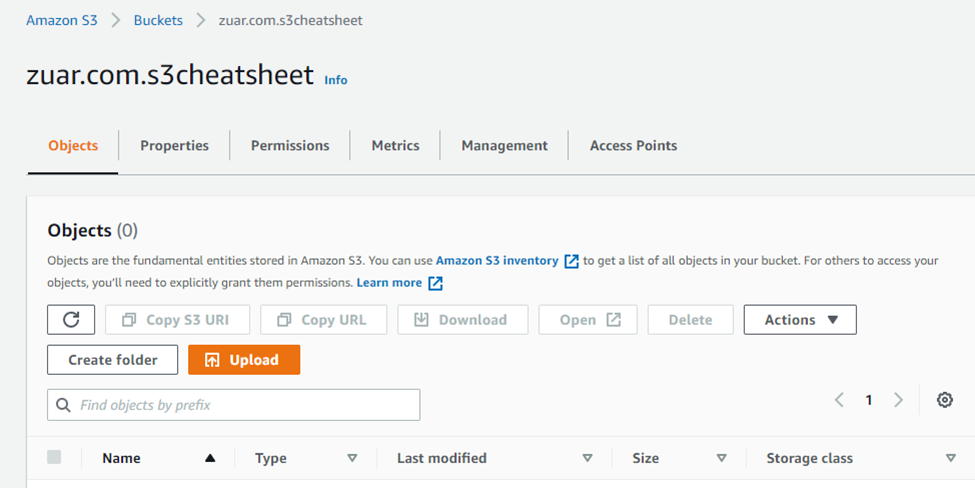
- On the "Object" tab, click on the “Upload” button.
- Click “Add files” to add the website files and use “Add folder” to add the website folders.
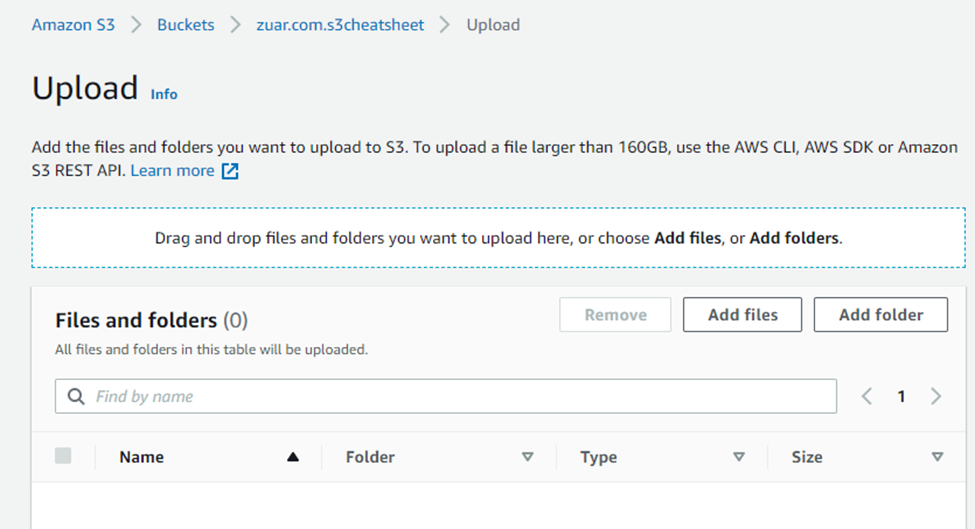
- Click on the “Upload” button. Upload should be done in a few minutes depending on content size.
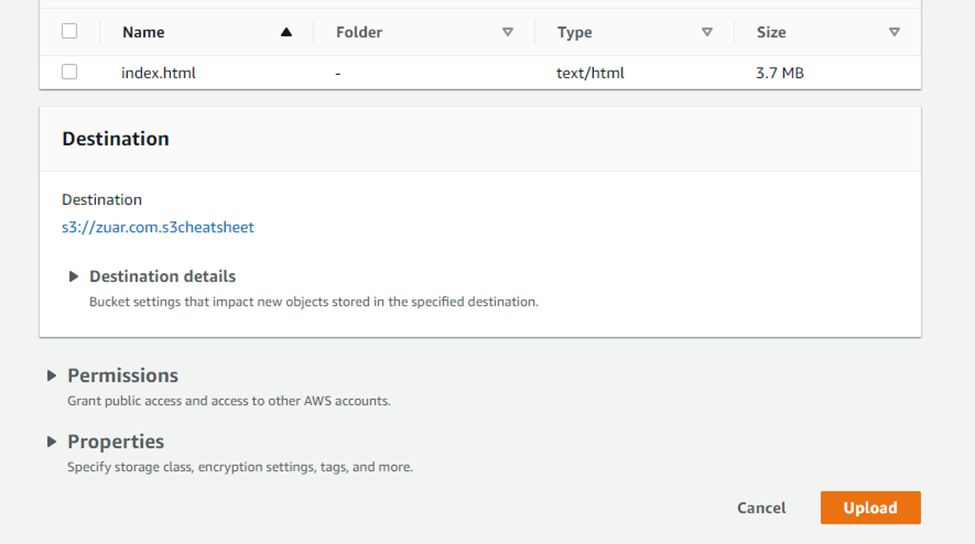
- After saving, click on the bucket website endpoint and it will display your website.
Step 3: Secure S3 bucket through IAM policies
- From S3 dashboard, click on the name of the bucket and then click on the “permissions” tab.
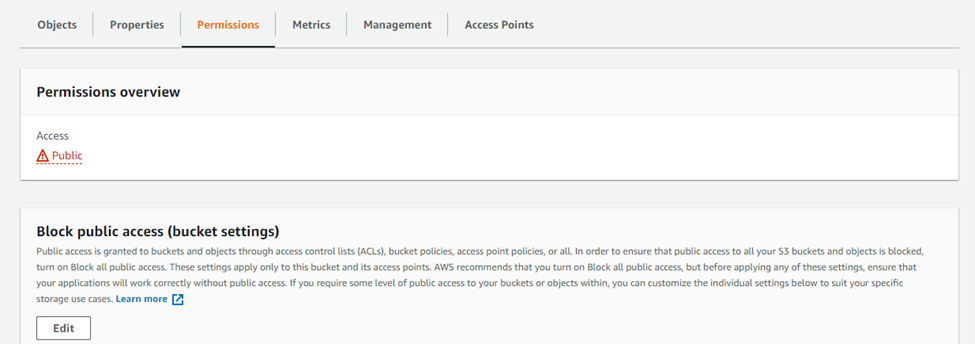
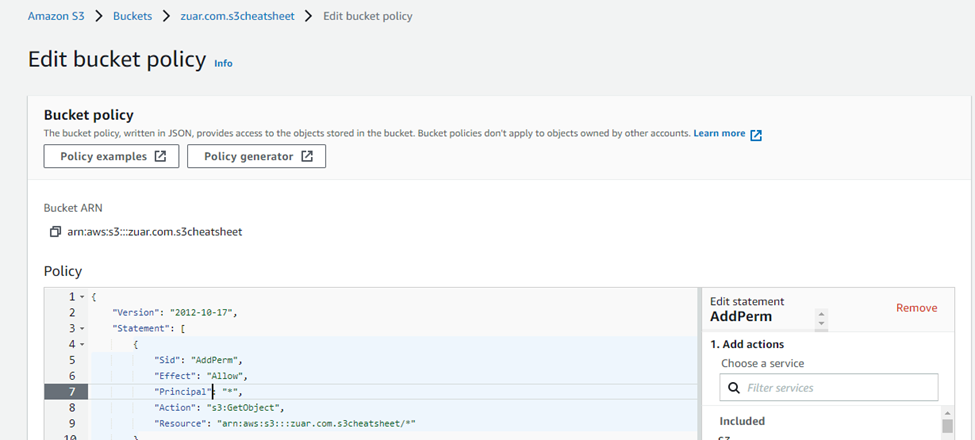
- Go to the “Bucket Policy” section and click on the “edit” button.

- Add the following bucket policy to it and make sure to replace bucket-name with the name of your bucket. Scroll down to the bottom and then click on the “save” button.
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"AddPerm",
"Effect":"Allow",
"Principal": "*",
"Action":["s3:GetObject"],
"Resource":["arn:aws:s3:::bucket-name/*"]
}
]
}
Step-4: Configure S3 bucket
- From S3 dashboard, click on the name of the bucket and then click on the “properties” tab.
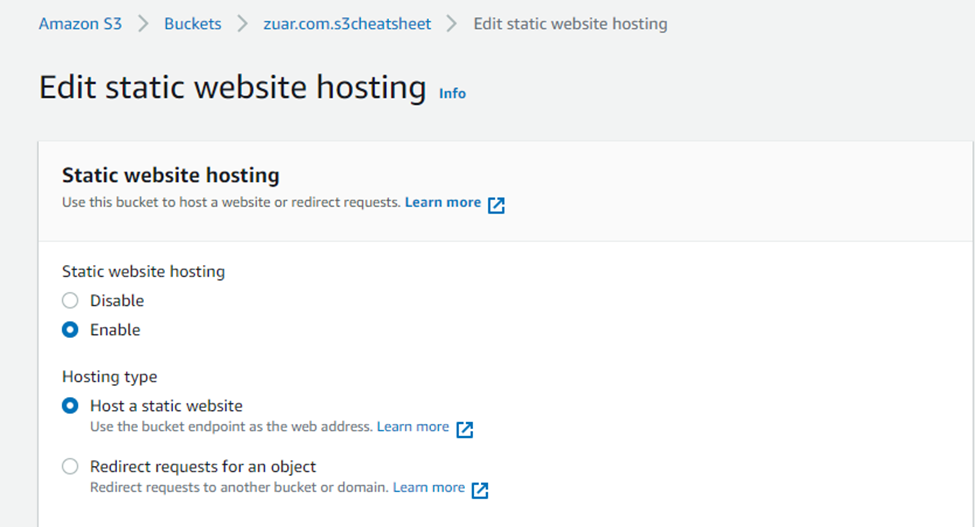
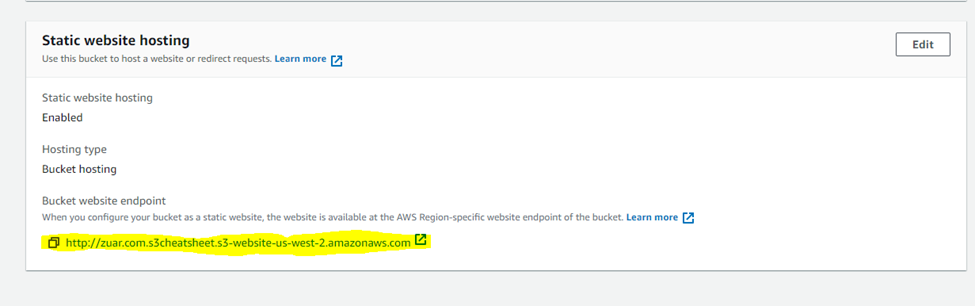
- Go to the “Static website hosting” section and click on its “Edit” button.
- Enter your website’s index and error HTML file name, click on “save changes”.
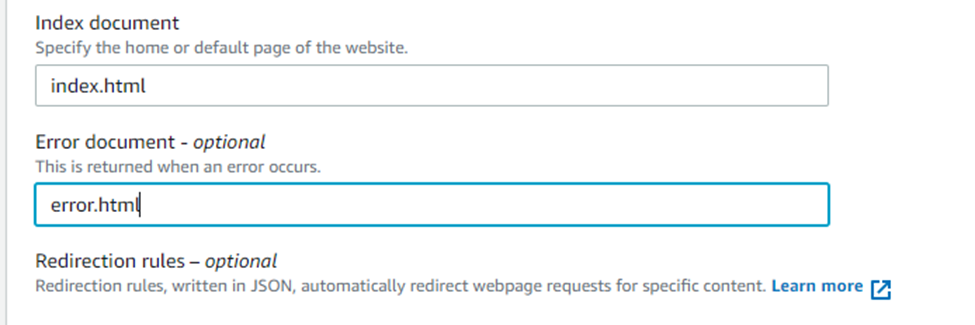
If you were to click on the bucket website endpoint as shown below, it would display your website.

AWS S3 Lifecycle Management
We can use S3 for system log storage. The requirement is to automatically move the log files to lower-cost storage classes like Amazon Glacier as it ages (let's say after 60 days) or remove all the objects when a specified date or time period is reached.
- From the S3 dashboard, click on the name of the bucket and then click on the “Management” tab.
- Enter a well-defined rule name and choose the rule scope to “Apply to all objects in the bucket”. Click on the checkbox “I acknowledge the rule…”.
- From the “Lifecycle rule actions” section, select the checkbox “Move current versions of objects between storage classes” and click on the “Add Transition” button.
- Enter the input field “Days after object creation”.
- Again, from the “Lifecycle rule actions” section, select the check box “Expire current versions of objects”.
- Enter the input field “Days after object creation”.
- Scroll down to the bottom and click on “Create Rule”.
Learn more about other Amazon databases such as RDS and Redshift.

What Next?
I hope this post will help you to get an overall idea about S3 and how best it can be used. The best way to get up to speed with AWS services is to learn by doing.
If you are looking to get the most out of your S3 data, consider scheduling a free data strategy assessment with Zuar. We'll show you how we can help automate and manage your data pipeline by, for example, connecting S3 to an analytics platform like Tableau to gain better insights more quickly and easily. Plus, our Runner solution can manage the processes involved with getting data into and out of S3 including integration, modelling, automation, monitoring, etc.
FAQ
What is a typical use case for Amazon S3 ?
Following are some use cases for S3:
- Backup and Storage– Provide data backup and storage services for others.
- Application Hosting– Provide services that deploy, install, and manage web applications.
- Media Hosting– Build a redundant, scalable, and highly available infrastructure that hosts video, photo, or music uploads and downloads.
- Software Delivery– Host your software applications that customers can download.
Is Amazon S3 a database
Amazon S3 is a distributed object storage service. In S3, objects consist of data and metadata. A data store is a repository for persistently storing and managing collections of data which include not just repositories like databases, but also simpler store types such as simple files, emails etc.
How does S3 store files?
In Amazon S3, buckets and objects are the primary resources, where objects are stored in buckets. Amazon S3 has a flat structure with no hierarchy like you would see in a typical file system. You can have folders within folders, but not buckets within buckets. You can upload and copy objects directly into a folder. Folders can be created, deleted, and made public, but they cannot be renamed. Objects can be moved from one folder to another.
Why is S3 so popular?
AWS S3 has modern technological storage features like high availability, multiple storage classes, low cost (only pay for what you use), strong encryption features, among other benefits.
How much data can S3 hold?
The total volume of data and the number of objects you can store are unlimited. Individual Amazon S3 objects can range in size from a minimum of 0 bytes to a maximum of 5 TB. The largest object that can be uploaded in a single PUT is 5 GB.
When should S3 be used?
When:
- Your storage or bandwidth needs grow beyond what you have and S3 is cheaper than upgrading your current solution.
- You move to a multiple-dedicated-server solution for failover/performance reasons and want to be able to store your assets in a single shared location.
- Your bandwidth needs are highly variable (so you can avoid a monthly fee when you're not getting traffic).
Is data stored in S3 always encrypted?
S3 by default does not encrypt the data stored into its service. But using the Server Side Encryption feature, if proper headers are passed (in REST), S3 will first encrypt the data and then store that encrypted data.
How many buckets can be created in S3?
By default, you can create up to 100 buckets in each of your AWS accounts. If you need more buckets, you can increase your account bucket limit to a maximum of 1,000 buckets by submitting a service limit increase.