Amazon Web Service’s Glue is a serverless, fully managed, big data service that provides a cataloging tool, ETL processes, and code-free data integration. These are services for data that is moved, transformations and managed both within and outside the AWS account. The biggest asset outside of its serverless architecture (no need to manage an EMR cluster) is that many of the data processes can be stood up inside the graphical user interface of the console, without writing code. Many parts of Glue can be used by other applications, an example is many AWS services have an option to catalog metadata within Glue; this is true for Amazon Athena, EMR, and Redshift.
But there are many limitations of AWS Glue compared to EMR (Elastic Map Reduce) or 3rd party solutions such as Runner. Despite the hype from AWS and their certified consultants, it is not a panacea for smaller data teams, and can be a burden to maintain. The detailed decision points will be highlighted later.
Related Article:
 Team Zuar
Team Zuar
Data Catalog
The data catalog can trace its existence back to Apache Hive Metastore in the Hadoop Ecosystem. For larger enterprises who jumped onto the 2010s big-data bandwagon, a data catalog became a crucial tool for data governance and data management. Mainly because there was no traditional management studio or client for HDFS datastores. Also, this type of capability can be used by data architects and scientists to manage slowly changing dimensions of data, and for data discovery at any time.
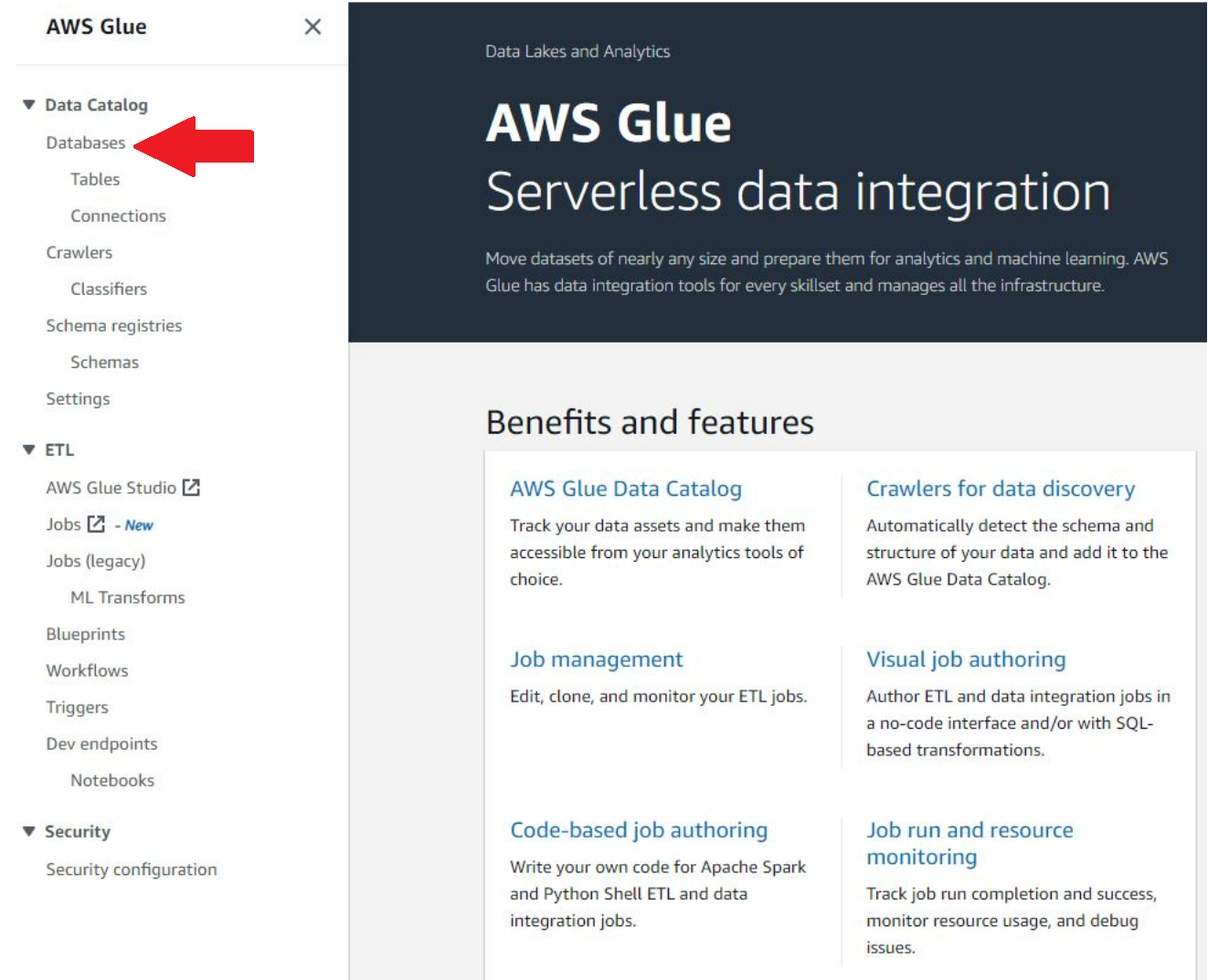
To get started with Glue and its data catalog, first go to the AWS console and search for 'AWS Glue'. The Glue console is shown below. The left-hand navigation options show two primary areas of focus: Data Catalog and ETL. The Data Catalog tab is not the most intuitive when getting started for the first time. First, navigate to the 'Databases' tab, because a new database will need to be defined. This is nothing more than typing a name and saving it.
Next, to populate the tables section, schema registries or to use the crawler (the other two main functions in Data Catalog) you need to first successfully connect to a data source. To instantiate this, click on the 'Connections' tab to start this process, and then click 'Add Connection'. The following configuration page comes up:
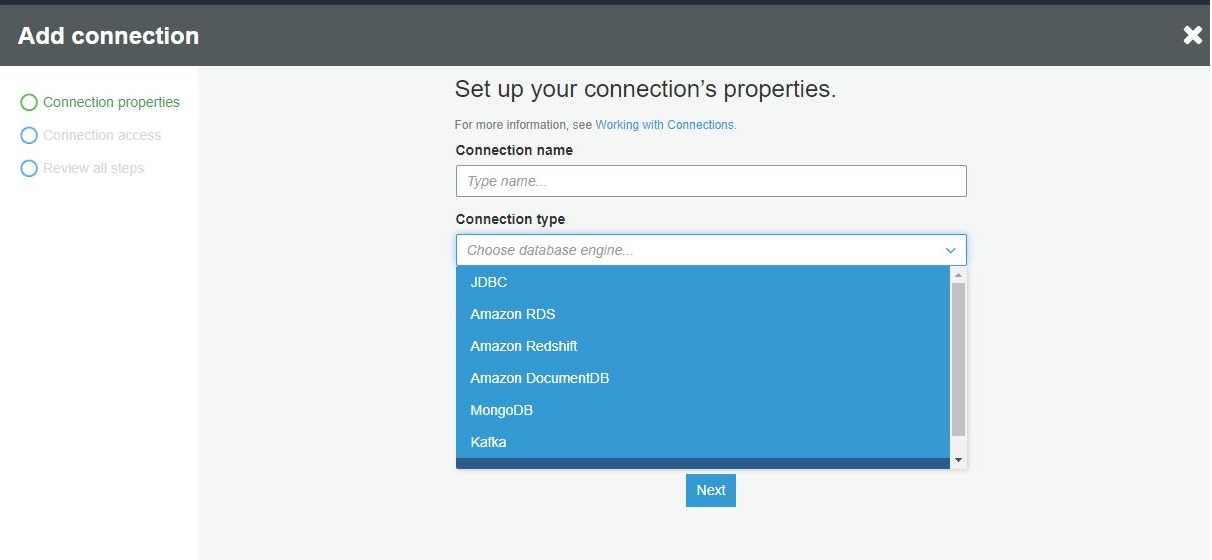
Glue supports generic JDBC, managed connections to RDS clusters, managed connections to Redshift, and managed connections to DocumentDB (the AWS version of MongoDB). Glue also supports Kafka streams (both MSK, the AWS managed Kafka) and any generic Kafka cluster you might have self-hosted, and finally a generic network connection.
Once the connection type is selected, depending on what it is, it may ask you to select the instance of the AWS managed service. If not, then it asks for the VPC that the target service is paired with, as well as any pertinent connection info for it like URL, username, password. The connection can then be tested before saving the configuration (it's best to not skip this step!).
Adding a table can happen in three ways. The first and preferred method is using a crawler. The second is by manual input, which entails physically typing out all the field names, their types, etc. The last is replicating from an existing schema, which is not possible from the first instance of setting up tables. To make tables using a crawler, the crawler must be configured prior.
The crawler is a managed metadata discovery service within Glue. Click on the 'Crawlers' tab and it will list any that have been previously configured. Press the 'Add Crawler' button to start configuring one. The page to start configuration is below:
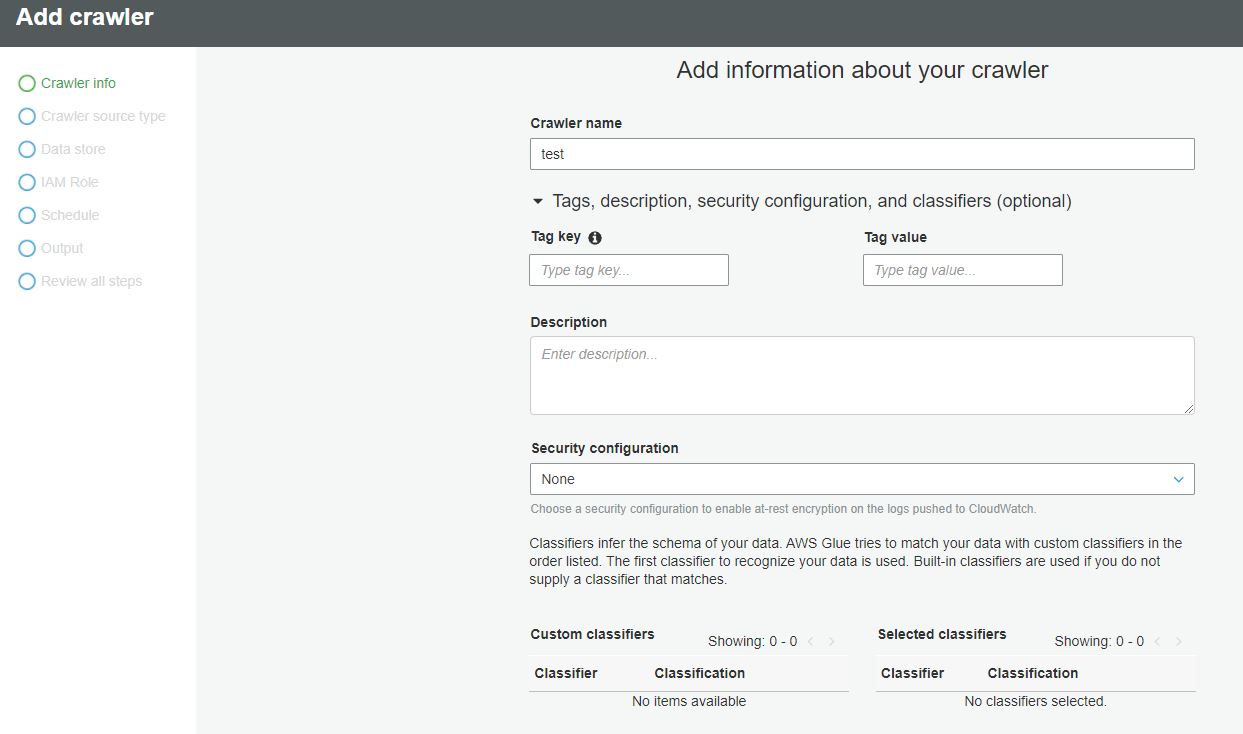
The only required field is 'Crawler name'. Tags description and the security configuration are optional. The next page is where the crawler source type is configured, as seen below...
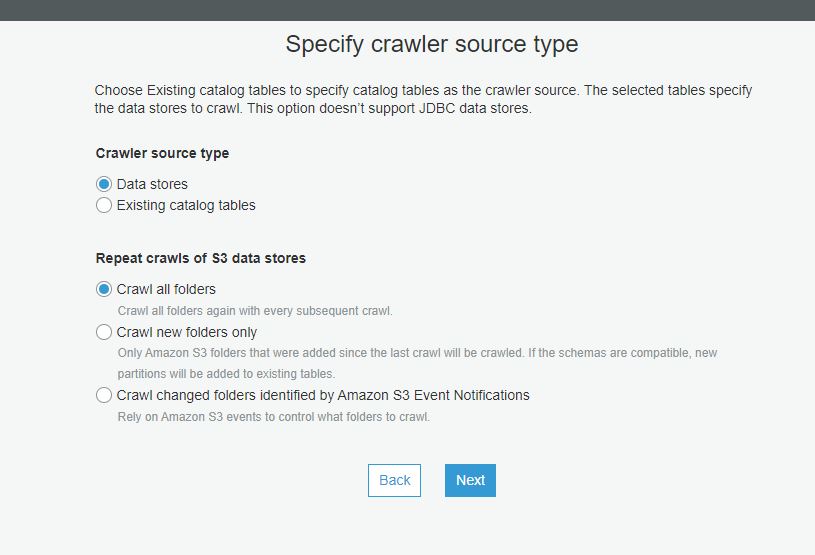
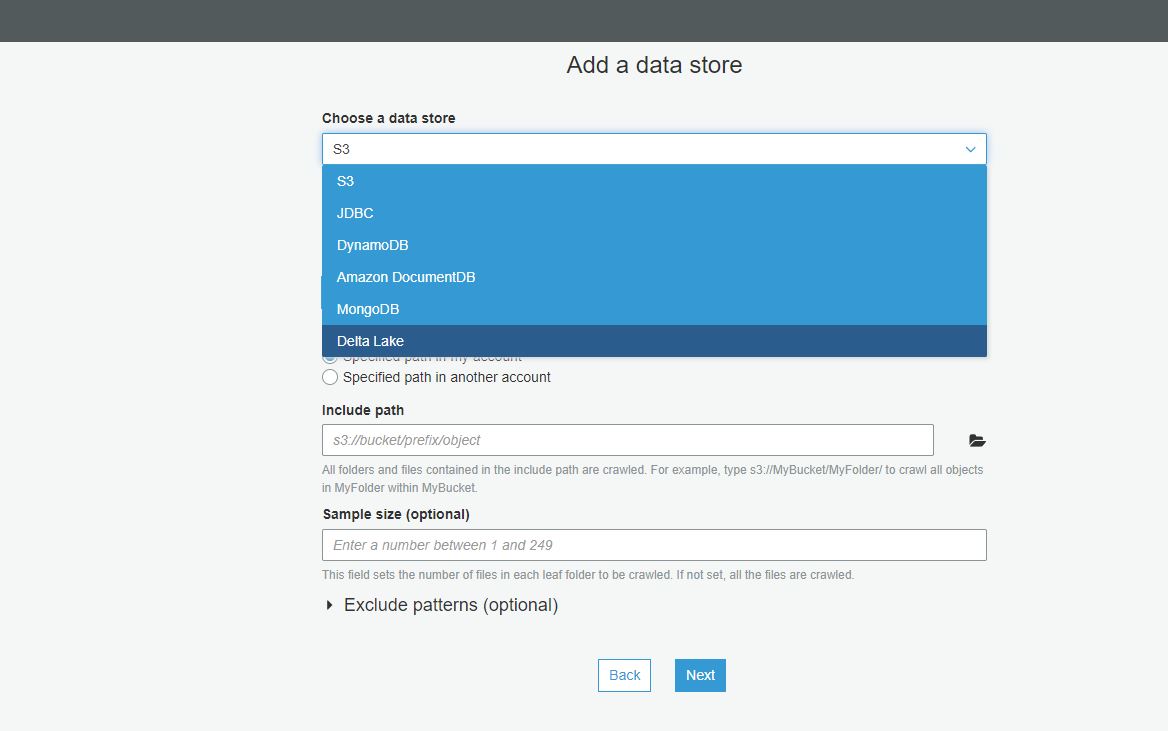
The next page is where you configure the actual source that the crawler will crawl. As seen below, it supports both internal to AWS services, as well as any JDBC connection, MongoDB and Databricks Delta Lake. S3 and DynamoDB are unique, in they do not need a connection previously configured like above. They have native support, and the tables or buckets are specified in this screen.
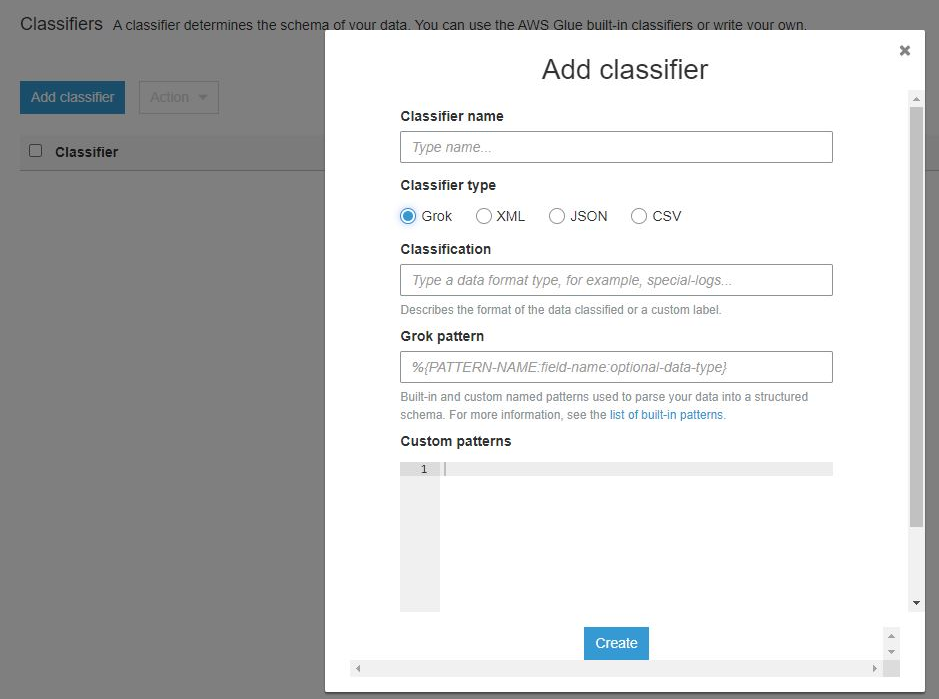
The remaining configuration consists of setting up an IAM role, scheduling crawler runs to keep the metadata up to date, and configuring its output. The last piece of functionality related to crawlers is classifiers, which are used on semi-structured data to define schemas which allows them to be used. It supports Grok, XML, JSON, and CSV.
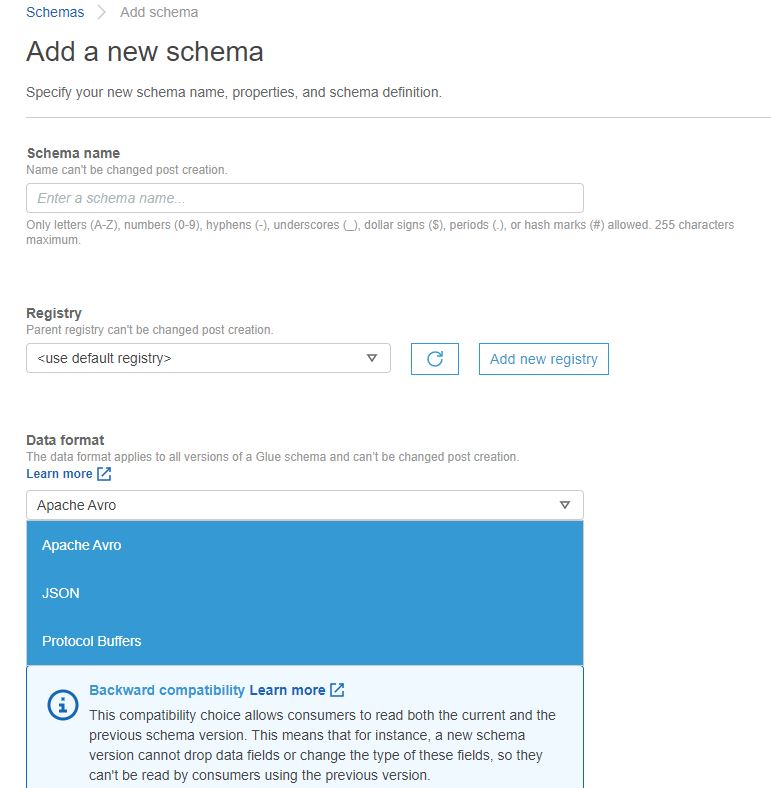
The last data catalog consideration is called a Schema Registry, which contains Schemas. The first step in using this is to make a schema registry, which is nothing more than filling out a name, possibly a description and optional tags. Making a schema is also fairly easy. As seen below, it supports Apache AVRO, JSON and Protobuf, and there are settings on allowing backwards and forwards compatibility, as well as a native versioning scheme.
ETL
AWS Glue is pushed as Amazon Web Services default method of ETL intra-platform data integration. Previously the way to create, configure and manage jobs was through a console GUI that looks very familiar to the data catalog console. In it you configure your job, data source, data target, and what transform to use (or you can supply custom code) as seen below.
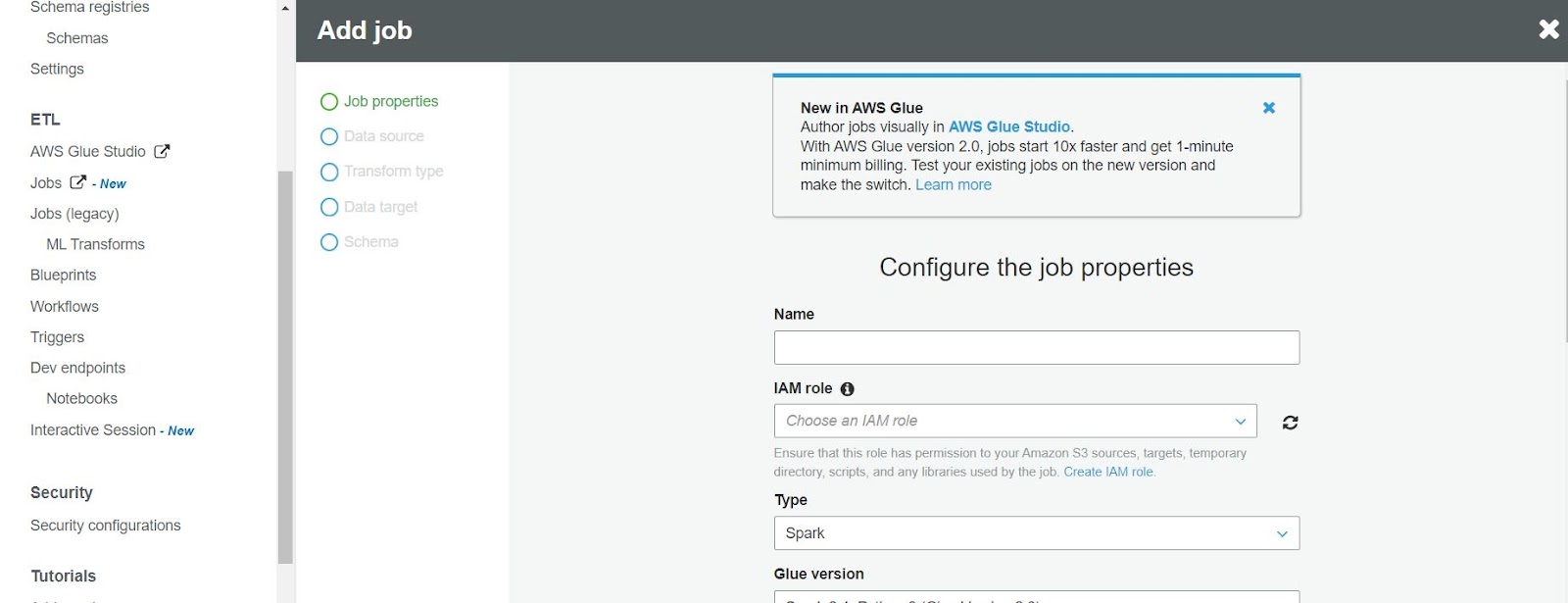
The recommended means of doing this now is via GlueStudio. GlueStudio is the native codeless all-the-way-to-hosted IDE for working with jobs. Blueprints, Workflows and Triggers are means of cataloging the Glue ETL jobs that have been created, and associating them with either templates or internal orchestration of when to run a job, be it on a schedule, an event or on-demand.
Though for greater scalability, flexibility, and automation for your ETL, check out the Runner platform.
Jobs
The job is the main unit of work that Glue provides, and before GlueStudio was a very frustrating task to get right. Glue studio opens up to a screen below:
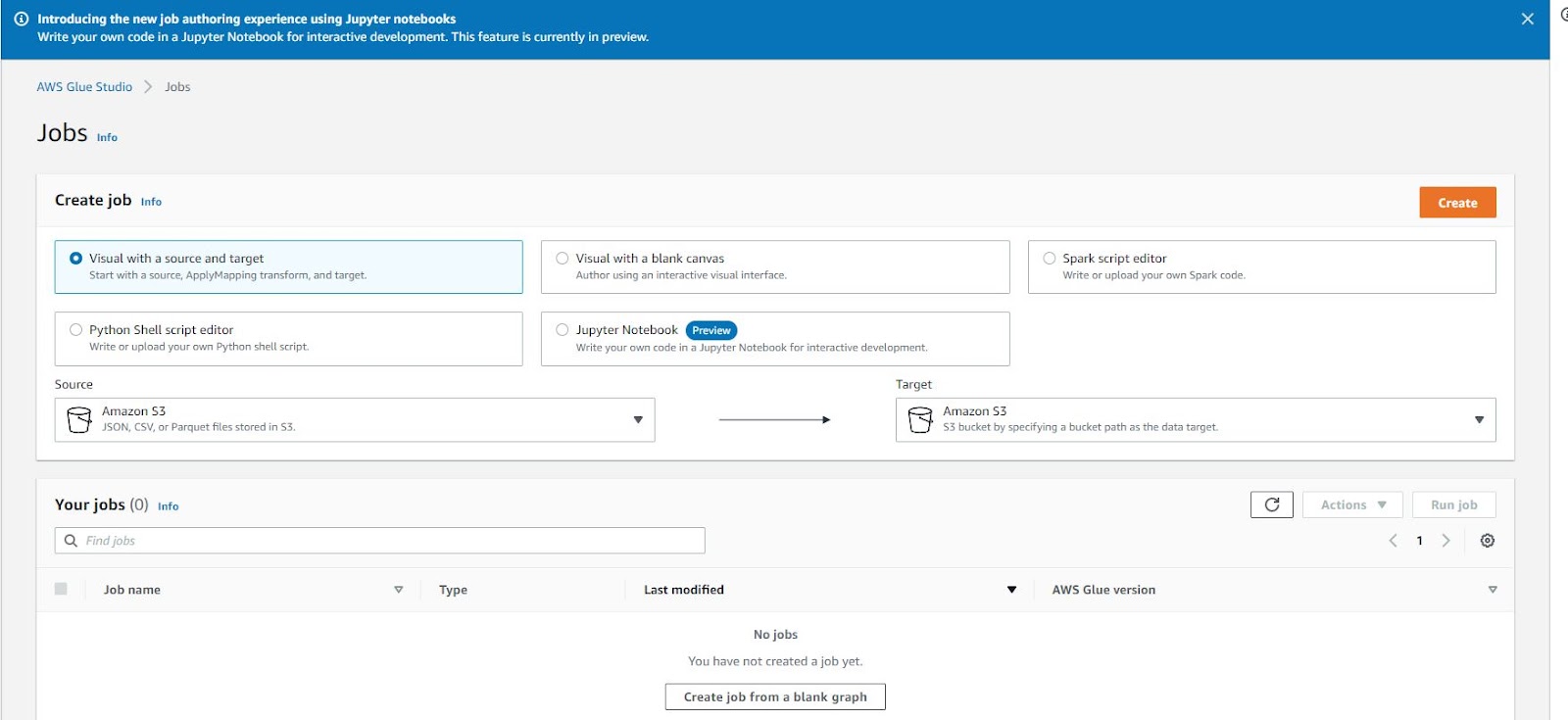
The 'Create Job' pane allows for the user to use a source and target in a visual manner, as below. The first two options open up this Graphical Development Environment.
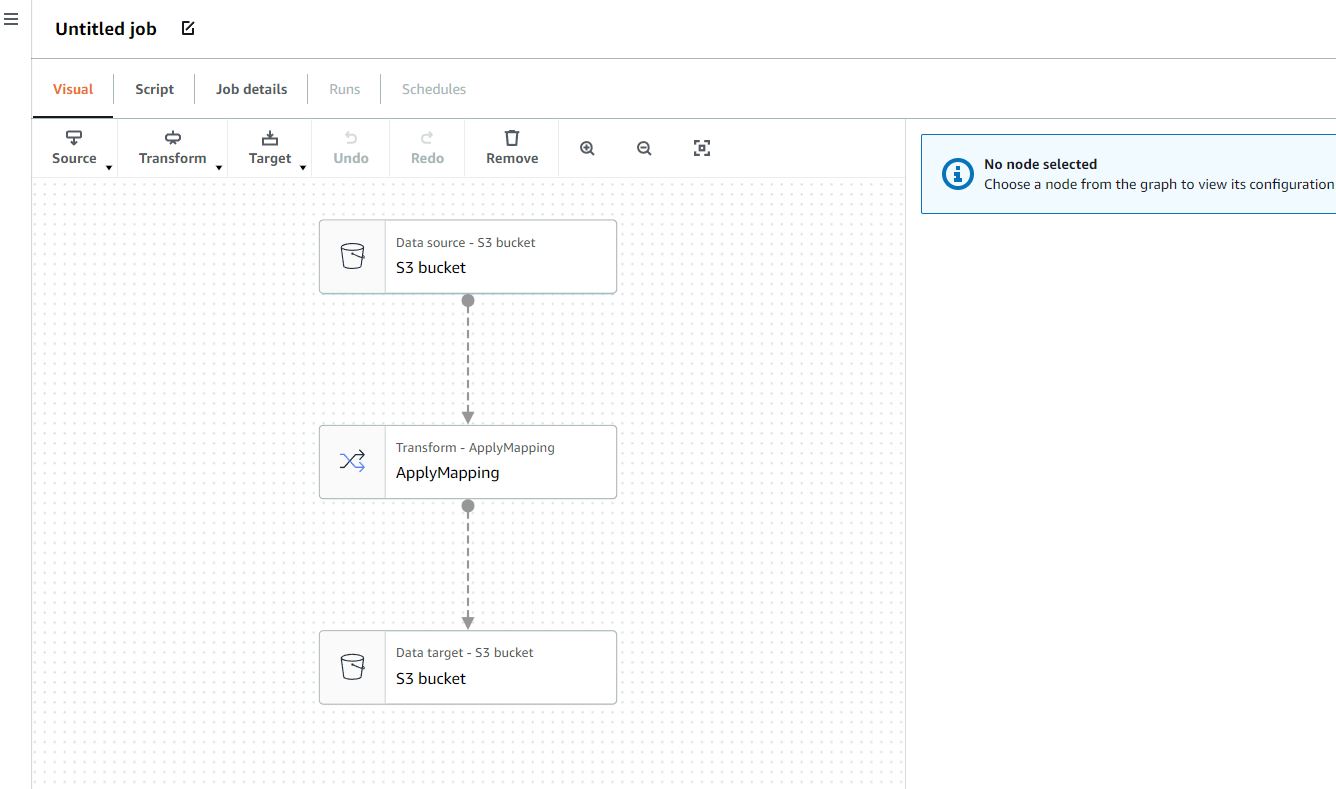
The source and target support almost every database, streaming technology and AWS managed service out there. It allows for a flow from Apache Kafka to S3, for example. As long as the data source and sink connections are configured properly (see above Connections section), it really is as simple as that.
The transformation is actually optional but, for example, if in this case it was necessary to map a parquet to a CSV this flow would suffice. There is however a tab for writing the code in python manually, and a mandatory 'Job Details' tab.
Part of the job settings are shown below. Most defaults will work fine for standard runs.
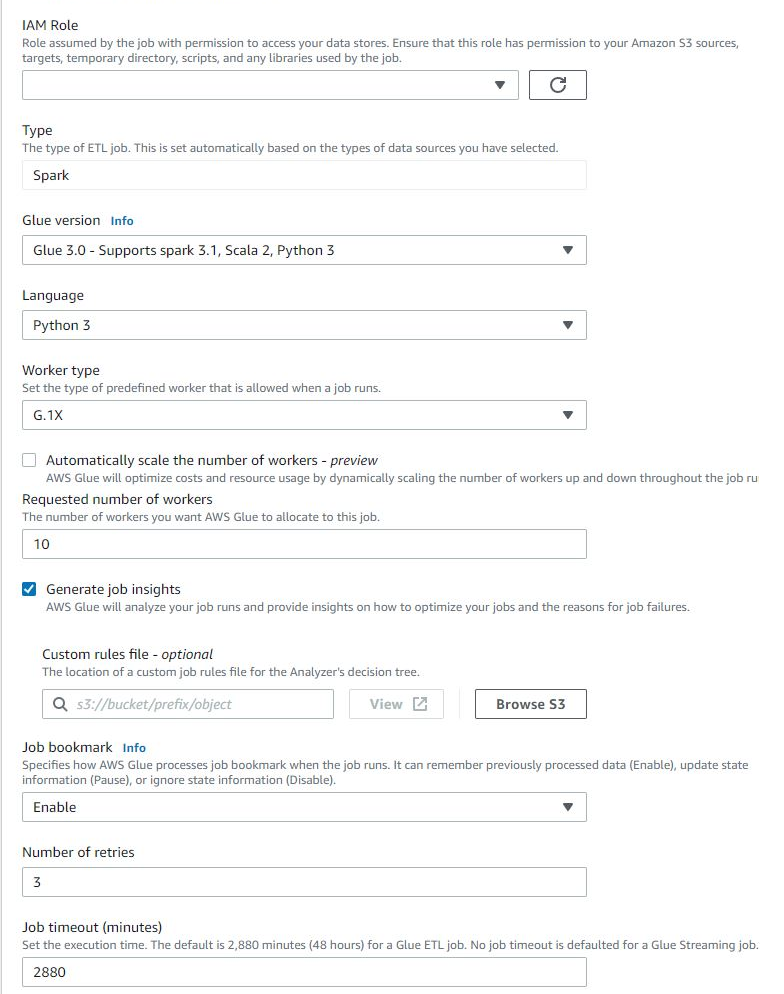
Glue now supports Spark customization that is extremely similar to what is possible with EMR. However, this can still be very frustrating when working with custom uploaded components such as the Libraries functionality. If this level of Spark tuning is needed, Glue may not be the best option.
The other means of configuring Glue jobs do not necessarily need this UI, in fact it now supports using a AWS managed Jupyter notebook. Spark scripts as well as plain Python scripts are supported, and the editor will even generate boilerplate code to use to configure the job properly. The bottom half of Glue studio is where save jobs are managed and edited once created.
There is a monitoring tab that shows all the different metrics one could care about after turning on a Glue job. Things such as how many runs, what is currently running, the timeline and most importantly the DPU (Data Processing Units) which are the calculated way of job runs translating into billing for a or many jobs, depending on their size and how many DPUs they consume in a run.
The connectors tab is interesting, as you can make a custom Athena (interactive query service), JDBC or Spark connector for Glue to consume unrelated to the connections in the data catalog. More importantly, there are many marketplace-maintained connectors for things like Glue to BigQuery, Glue to Snowflake. However these connectors have extra costs associated with them, and incur more advanced networking, IAM and configuration than a S3 to S3 flow for example. A not uncommon price point for a 3rd-party Glue connector is $250/mo. If you need to connected to a lot of different data sources, as most organization do, you can see how individual connector fees can quickly add up.
Visit here see what connectors are available.
When Should Glue Be Used?
If a company is very small and their product isn't tech, so there aren't many data engineers or devops resources, then Glue can be a force multiplier. As long as jobs are kept in check and scaled correctly, and the features that are absolutely necessary are leveraged, then this holds true. But that's a LOT of ifs, ands & buts.
If the company is large, growing or scaling soon... or if the company has data engineers, dev ops and others, then Glue is not the right solution. The time spent fighting with Glue or accepting its limitations, as well as the frustration many developers experience trying to push their code to Glue for execution, quickly eats up any cost savings.
Organizations looking for robust ETL/ELT capabilities can make a more confident, long-term choice with a solution like Runner. The platform has the bells and whistles to establish scalable data pipelines, supporting an organization through all stages of its growth. And you can save time by having a quick chat with Zuar's data specialists to determine if Runner is a good fit based on your specific needs.