Getting Started with AWS Data Pipeline
AWS data pipeline is a tool from Amazon Web Services that offers automation in data transportation. Data processing and transportation is provided between different AWS compute, storage, and on-premises data sources. With the tool you can move the processed data to AWS services like Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR with the help of AWS Data Pipeline, while still having frequent access to your data wherever it is stored.
The business logic for our data processing requirement is first specified in a pipeline definition. The pipeline is made up of activities that specify the tasks to be carried out, data nodes that specify the places and kinds of input and output data, and a schedule that specifies the order in which the activities are to be completed. With this data transfer tool, the subsequent procedure starts automatically once the prior one has been properly completed.

Components of the AWS Data Pipeline
The primary elements of the AWS Data Pipeline are as follows:
- Data Nodes (Source/Destination): Source data nodes are locations where a pipeline extracts information and Destination data nodes are the location where extracted/transformed data are outputted after being processed. Both data lakes and data warehouses are options for destination data nodes. This data can be loaded immediately into tools for data visualization. SqlDataNode, DynamoDBDataNode, RedshiftDataNode, S3DataNode are the types of data nodes available for pipeline activity.
- Activities: Activities are the processes by which SQL queries are executed on databases where data is transformed from one data source to another.
- Workflow: Workflow involves arranging jobs in a pipeline according to their dependencies. Dependencies and sequencing are determined when it executes.
- Preconditions: Prior to scheduling the activities, prerequisites must be met. For instance, if you want to move data from Amazon S3 you must first determine whether the data is present there or not. The activity will be carried out if the prerequisite is met.
- Actions: It updates the state of your pipeline by, for example, sending you an email or setting off an alarm.
- Monitoring: Constant monitoring is necessary to guarantee data accuracy, speed, data loss, and efficiency. As data size grows, the significance of these checks and monitoring increases.
- Pipelines contain the following...
- Pipeline Components: Pipeline components are mentioned above.
- Instances: An instance is created after all the components have been assembled and contain the data needed to perform a certain operation.
- Attempts: When an operation fails, the 'attempts' feature of the AWS Data Pipeline tries performing it again.
- Task runner: Extracts tasks for execution from the data flow. The status is updated after the task is complete. The procedure ends when the task is finished. If it fails, the task runner looks for a previous attempt to retry the task before starting over, and repeats the procedure until all pending tasks have been finished.

Benefits of AWS Data Pipeline
- Simple-to-use control panel with predefined templates for most AWS databases.
- Ability to spawn clusters and resources only when needed.
- Ability to schedule jobs only on specific time periods.
- Full security suite protecting data while in motion and rest. AWS’s access control mechanism allows fine-grained control over who can use what.
- Fault-tolerant architecture relieves users of all the activities related to system stability and recovery.
However, managing AWS resources effectively goes beyond mere data transportation. It's imperative to also improve your AWS security posture by implementing best practices that encompass all components of the AWS architecture, including aspects like continuous learning and the principle of least privilege. These measures ensure not only efficient data handling but also safeguard valuable information from potential threats and vulnerabilities.

Cons of AWS Data Pipeline
With a very thorough control panel, AWS Data Pipeline has a lot of potential as an ETL platform as a web service, but it has cons for particular business scenarios.
- If the data stores (both input and output) are from third-party services (on-premise, legacy database system or database exist outside of AWS world), implementation of an AWS data pipeline may not be viable.
- It is not a service that is good for beginners. Using these services for the first time can be complicated and challenging. It would be difficult to use AWS Data Pipeline if you have no experience utilizing other AWS services. This is due to the fact that this service contains numerous modules that you must understand in advance, and that it is regarded as a complex service for a newbie. The way Data Pipeline represents preconditions and branching logic can seem complicated to a newcomer.
- Data Pipeline connects seamlessly with many AWS components because it was created specifically for the AWS ecosystem. If you want to pull in data from third-party services, AWS Data Pipeline is not the best option. With several installations and configurations to be handled on the compute resources, using data pipelines and on-premise resources might be cumbersome.
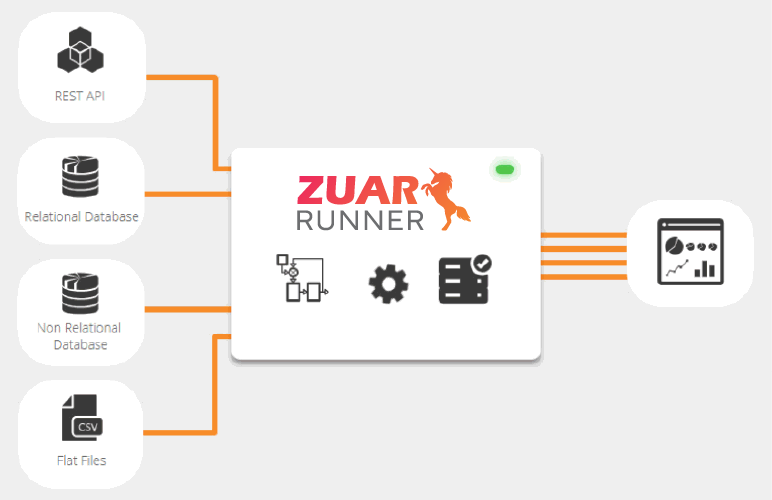
There are other tools available that complete complex connections much more easily. Platforms like Zuar Runner or Apache Airflow are typically better suited for most of these situations.
Learn more about Runner:


IAM Roles for AWS Data Pipeline
AWS Data Pipeline requires two IAM (Identity & Access Management) roles:
- Access to AWS resources through AWS Data Pipeline is controlled by the pipeline role. This role is described in the role field of pipeline object declarations.
- The access that applications running on EC2 instances, including those in Amazon EMR clusters, have to AWS resources is controlled by the EC2 instance role. This role is described in the resourceRole field of pipeline object descriptions.
Each role has one or more permission policies attached to it that determine the AWS resources that the role can access, and the actions that the role can perform.

Sample Policy JSON
Allows Data Pipeline and Data Pipeline managed EMR clusters to call AWS services on your behalf.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:*",
"datapipeline:DescribeObjects",
"datapipeline:EvaluateExpression",
"dynamodb:BatchGetItem",
"dynamodb:DescribeTable",
"dynamodb:GetItem",
"dynamodb:Query",
"dynamodb:Scan",
"dynamodb:UpdateTable",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateSecurityGroup",
"ec2:CreateTags",
"ec2:DeleteTags",
"ec2:Describe*",
"ec2:ModifyImageAttribute",
"ec2:ModifyInstanceAttribute",
"ec2:RequestSpotInstances",
"ec2:RunInstances",
"ec2:StartInstances",
"ec2:StopInstances",
"ec2:TerminateInstances",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:DeleteSecurityGroup",
"ec2:RevokeSecurityGroupEgress",
"ec2:DescribeNetworkInterfaces",
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface",
"ec2:DetachNetworkInterface",
"elasticmapreduce:*",
"iam:GetInstanceProfile",
"iam:GetRole",
"iam:GetRolePolicy",
"iam:ListAttachedRolePolicies",
"iam:ListRolePolicies",
"iam:ListInstanceProfiles",
"iam:PassRole",
"rds:DescribeDBInstances",
"rds:DescribeDBSecurityGroups",
"redshift:DescribeClusters",
"redshift:DescribeClusterSecurityGroups",
"s3:CreateBucket",
"s3:DeleteObject",
"s3:Get*",
"s3:List*",
"s3:Put*",
"sdb:BatchPutAttributes",
"sdb:Select*",
"sns:GetTopicAttributes",
"sns:ListTopics",
"sns:Publish",
"sns:Subscribe",
"sns:Unsubscribe",
"sqs:CreateQueue",
"sqs:Delete*",
"sqs:GetQueue*",
"sqs:PurgeQueue",
"sqs:ReceiveMessage"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": "iam:CreateServiceLinkedRole",
"Resource": "*",
"Condition": {
"StringLike": {
"iam:AWSServiceName": [
"elasticmapreduce.amazonaws.com",
"spot.amazonaws.com"
]
}
}
}
]
}
Creating Pipelines Using the Console
We can create a pipeline using the AWS Data Pipeline architect rather than a template. The example pipeline that we created in this section demonstrates using the architect to create a pipeline that copies files from a dynamoDB table to an S3 bucket based on a schedule.
**Please refer to the IAM roles for AWS data pipelines and create if required.**
**Don't forget to bookmark these instructions!**
- Open the AWS Data Pipeline console at https://console.aws.amazon.com/datapipeline/.
- Create a new pipeline.
- Under Security/Access, leave 'Default' selected for IAM roles.
If you have created your own IAM roles, choose 'Custom' and then select your roles for the Pipeline role and EC2 instance role. - You also configure the schedule for the activity to run and the AWS resource that the activity uses to run.
- Choose 'Edit' in Architect.


We have added and configured an EmrActivity that copies data from a DynamoDB table to Amazon S3.

For DataNodes you specify Amazon S3 location as the destination.


Once components are configured in the pipeline Save, Activate, and Monitor until Finished.

Once the execution is finished, navigate to your bucket location and verify if the DB files backup is copied in the correct S3 path.
Pipeline Definition (JSON Format)
{
"objects": [
{
"failureAndRerunMode": "CASCADE",
"resourceRole": "CDTestDataPipelineResourceRole",
"role": "CDTestDataPipelineRole",
"pipelineLogUri": "s3://cdtestbucket00/cdfolder/",
"scheduleType": "ONDEMAND",
"name": "Default",
"id": "Default"
},
{
"output": {
"ref": "S3BackupLocation"
},
"input": {
"ref": "DDBSourceTable"
},
"maximumRetries": "2",
"name": "TableBackupActivity",
"step": "s3://dynamodb-dpl-#{myDDBRegion}/emr-ddb-storage-handler/4.11.0/emr-dynamodb-tools-4.11.0-SNAPSHOT-jar-with-dependencies.jar,org.apache.hadoop.dynamodb.tools.DynamoDBExport,#{output.directoryPath},#{input.tableName},#{input.readThroughputPercent}",
"id": "TableBackupActivity",
"runsOn": {
"ref": "EmrClusterForBackup"
},
"type": "EmrActivity",
"resizeClusterBeforeRunning": "true"
},
{
"readThroughputPercent": "#{myDDBReadThroughputRatio}",
"name": "DDBSourceTable",
"id": "DDBSourceTable",
"type": "DynamoDBDataNode",
"tableName": "#{myDDBTableName}"
},
{
"directoryPath": "#{myOutputS3Loc}/#{format(@scheduledStartTime, 'YYYY-MM-dd-HH-mm-ss')}",
"name": "S3BackupLocation",
"id": "S3BackupLocation",
"type": "S3DataNode"
},
{
"name": "EmrClusterForBackup",
"coreInstanceCount": "1",
"coreInstanceType": "m3.xlarge",
"releaseLabel": "emr-5.23.0",
"masterInstanceType": "m3.xlarge",
"id": "EmrClusterForBackup",
"region": "#{myDDBRegion}",
"type": "EmrCluster",
"terminateAfter": "10 Minutes"
}
],
"parameters": [
{
"description": "Output S3 folder",
"id": "myOutputS3Loc",
"type": "AWS::S3::ObjectKey"
},
{
"description": "Source DynamoDB table name",
"id": "myDDBTableName",
"type": "String"
},
{
"default": "0.25",
"watermark": "Enter value between 0.1-1.0",
"description": "DynamoDB read throughput ratio",
"id": "myDDBReadThroughputRatio",
"type": "Double"
},
{
"default": "us-east-1",
"watermark": "us-east-1",
"description": "Region of the DynamoDB table",
"id": "myDDBRegion",
"type": "String"
}
],
"values": {
"myDDBRegion": "us-east-1",
"myDDBTableName": "Music",
"myDDBReadThroughputRatio": "0.25",
"myOutputS3Loc": "s3://cdtestbucket00/cdfolder2/"
}
}Related Article:
 Team Zuar
Team Zuar

Choosing the Best Solution for You
As stated above, AWS Data Pipeline has a number of advantages, particularly when working exclusively within the AWS ecosystem. However, when it's necessary to integrate with third-party data sources, AWS Data Pipeline won't be your best option.
Additionally, for non-technical users and those who do not have in-depth experience with AWS services, AWS Data Pipeline may be unnecessarily difficult to work with.
Often a better solution is to implement a more agnostic ETL/ELT platform such as Runner. Zuar Runner makes setting up data pipelines simple. With a multitude of pre-built connectors, Runner can connect both your AWS and non-AWS services into a single end-to-end data pipeline.
Our services team is experienced in helping both experienced and beginner users ram up to use the platform, and can assist you every step of the way! Learn more by talking with one of our data experts:
