
Amazon EMR (Elastic Map Reduce) is a managed 'Big Data' service offering from AWS (Amazon Web Services). With it, organizations can process and analyze massive amounts of data.
Unlike AWS Glue or a 3rd party big data cloud service (e.g. Databricks), EMR is not fully managed (though AWS EMR Studio is looking to be a competitor in this market).
A beginner can leverage EMR, however nuances of the open-source frameworks such as Apache Hadoop, Apache Spark, and Presto should be reviewed before instantiating any EMR clusters. Also, EMR is a fairly expensive service from AWS due to the overhead of big data processing systems, and it also is a dedicated service. Even if you aren't executing a job against the cluster, you are paying for that compute time and its supporting ensemble of services. Forgetting an EMR cluster overnight can get into the hundreds of dollars in spend - certainly an issue for students and moonlighters. So please remember to double check the status of any cluster you turned on, and be prepared for larger costs than EC2, S3 or RDS.
If you need more of an ETL-type setup, be sure to check out Zuar's Runner solution. Enjoy a robust data pipeline that automates everything repetitive.
The 'Applications' EMR Supports
If we break down the name Elastic Map Reduce to two elements: 1. Elastic, which decorates sister service names like EC2 or ELB or EBS, insinuates elasticity of the cloud and an unofficial denotation of an AWS flavor of a service offering. 2. Map Reduce which is a programming paradigm that is the central pattern behind the open source big data software Apache Hadoop, which gave way to the Hadoop Ecosystem (ensemble of supporting applications like YARN and ZooKeeper and standalone applications like Spark).
Ironically, Apache Hadoop had a meteoric rise after the 2008 financial crisis, as a way for corporations to 'cheaply' store and analyze data in lieu of legacy OLAP (Online Analytical Processing) data warehouses, which were very costly in both licensing, hardware, and operation. Furthermore, pre 2012, public cloud was very taboo for most larger technology organizations. Hadoop gave those teams and executives the best of all worlds, having innovative technology, embracing the open source movement of the early 2010s, and the security and control of on premise systems.
The honeymoon with Hadoop ended early. By the mid 2010s public cloud and specifically AWS skyrocketed in adoption in all sectors. They quickly appealed to the large Hadoop users in banking, defense and healthcare... the sectors originally most invested in on premise big data technology.
Also, the ease of 'blob' storage solutions with semi structured data with external SQL support such as Athena, an access and consumption pattern that Hadoop brought to market with Hive and Impala was its death knell.
The operating costs, complexity of keeping Hadoop clusters running and expansion and the ever growing frustration of having to manage multiple services just to run a query also added to the frustration with having Hadoop, especially on premise clusters.
Still, the Hadoop API is extremely extensible and in some instances still has very relevant and elegant use cases. Hadoop’s arguably largest legacy is it gave birth to Apache Spark, which is one of the widest used Analytics tier applications across all industries. Also, HBase has very relevant NoSQL use cases along with Hive (mentioned earlier) which allows external SQL on semi-structured files such as ORC and Parquet.
To answer the original question of what EMR supports out of this ecosystem: Hadoop, Spark, Hbase, Hive, Hudi, and Presto. Hudi is a newer player in the ecosystem, its pronounced “hoodie” and is an acronym for Hadoop Upserts deletes and incrementals, which gives Hadoop many features that are in other data warehouses on the cloud. Presto is a query engine that is native to Hadoop files systems, as well as S3, allowing for hybrid workloads and federated query execution.
The configuration for these systems is partially taken care of using the EMR console commands. Others will have to be configured post spin up. There are also a few ways to interact with these tools. The original way is using S3 to drop data as well as your map reduce or spark job to the EMR cluster for execution and output. This method of interaction is very antiquated. AWS realized this and added Jupyter notebook support, and most recently EMR studio.

How to Initialize an EMR Cluster
Since Spark is the most popular EMR flavor, we will be walking through how to spin up a Spark cluster.
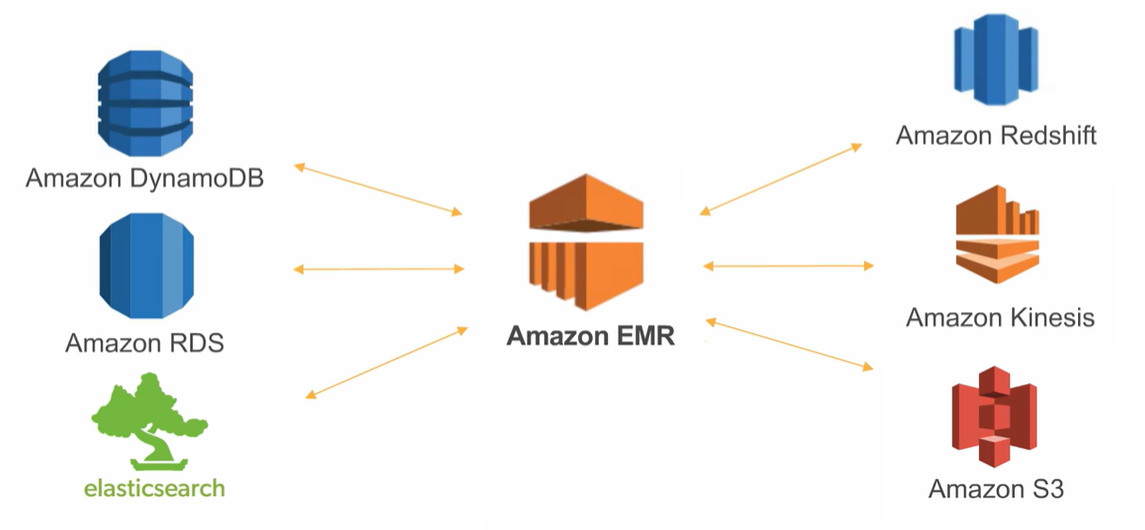
The original means of interacting with EMR is the 'How Elastic MapReduce Works' section seen below. The EMR Studio is a semi-integrated development environment with the ability to provision EMR clusters, and is very close to a Databricks-style of interaction (but is more expensive to use). Finally there's the 'Notebooks' option. These notebooks exist outside the scope of a cluster but need one provisioned to work (this can be changed) and can be integrated to a git or codecommit for code versioning. The config of the clusters is completely separate, and there is a cost to having notebooks on top of the EMR cost.
Quick EMR Configuration
If using the traditional method, 'Step Execution' will pick up your code and data, run the Spark job, and then terminate. This is less efficient but ensures no cluster resources are idle and costing money. Regardless of what process is used, the S3 folder will need to be selected (it defaults to creating one, this has been redacted).
Under 'Software Configuration', you can pick a release version and one of the four very popular flavors. For our example we're selecting Spark that comes with Zeppelin (a UI notebook environment native to Spark, redundant to notebook offering). If we were using Hive, it's recommended to use AWS Glue as the metadata provider for the hive external table contexts.
Next is the hardware configuration, which has implications for optimizations and job sizes, while the scaling option will auto-scale larger workloads. 'Auto-termination' should always be selected to ensure that excess charges are not incurred.
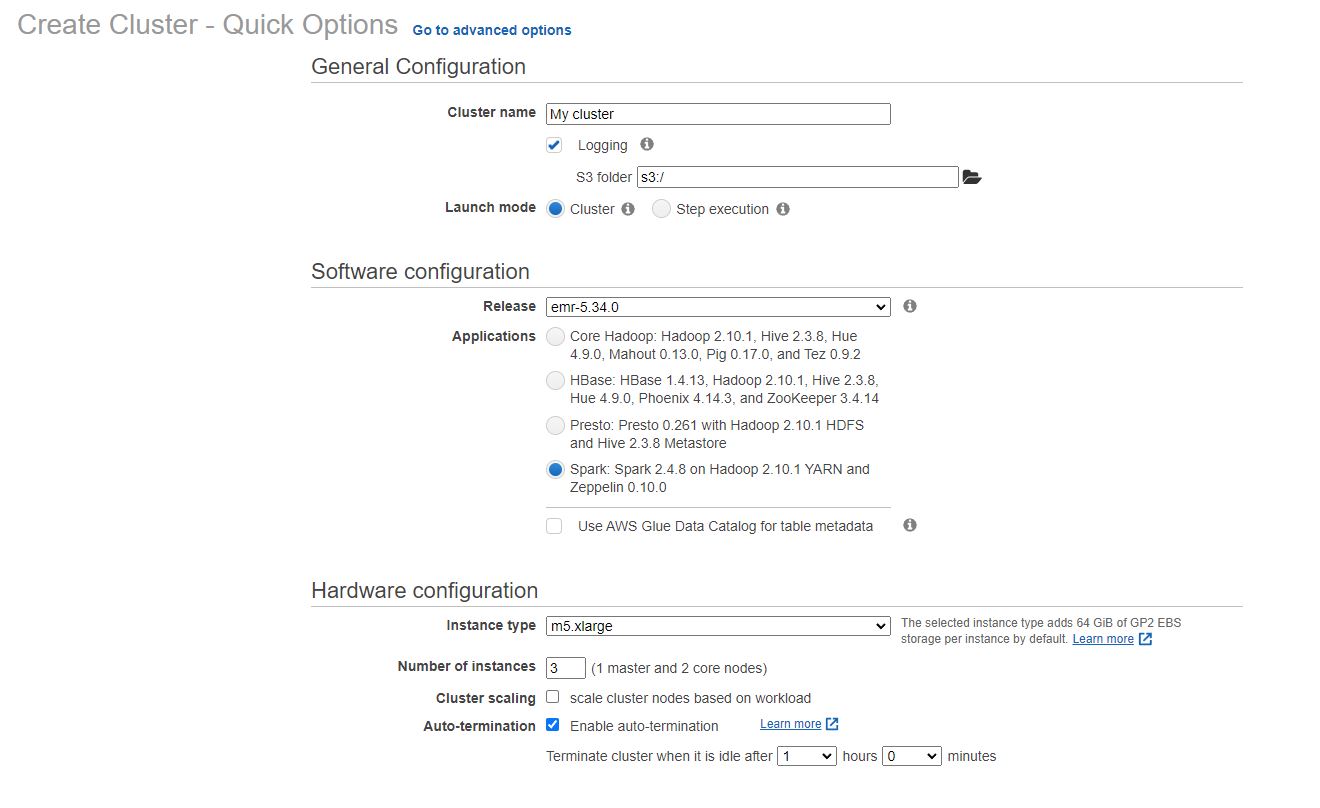
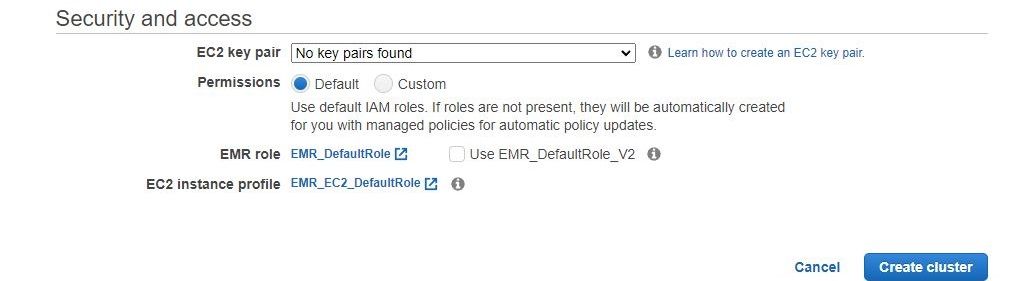
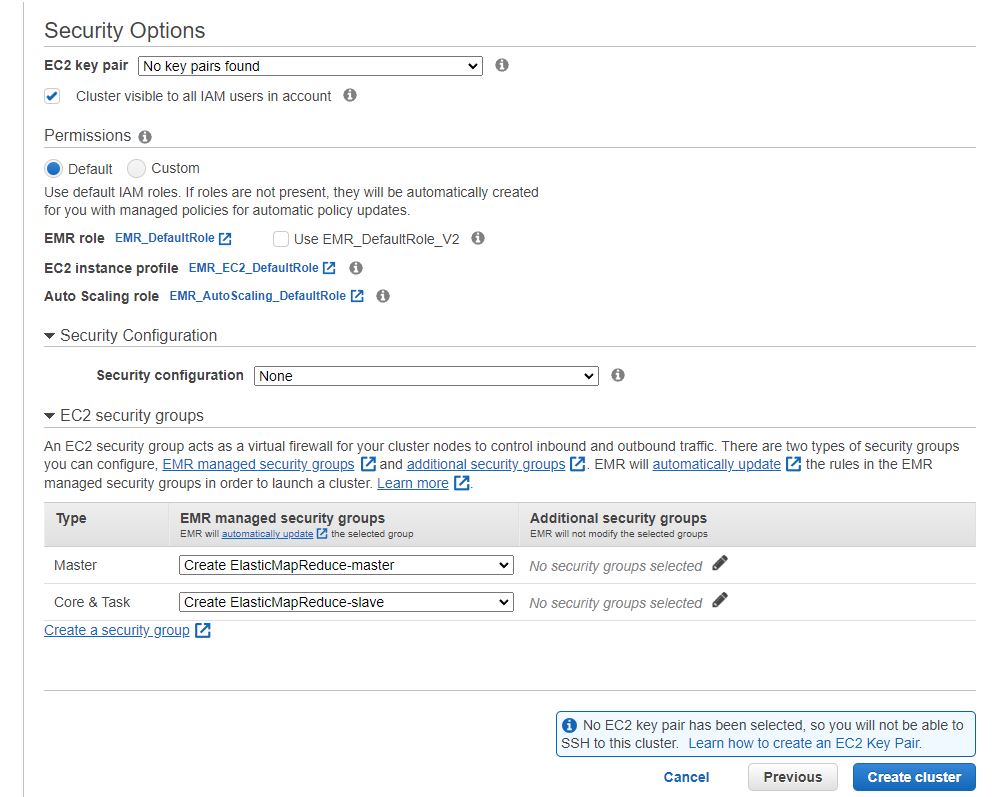
Finally, for security the key pair allows you to get CLI access into the cluster, and the permissions can be tuned to allow for a greater scope of access to the EMR resources, if needed.
Advanced EMR Configuration
Here you have to select what is needed for Spark, as it always defaults to what is needed in Hadoop. Also, you could omit Zeppelin if you plan on using the notebooks or even deploy notebooks on the cluster, and omit both Zeppelin and the managed notebooks! Having multiple master nodes is only useful for extremely high-throughput jobs. The Glue Hive metadata is also an option here. For the software settings the available configuration files to pass in are: capacity-scheduler, core-site, hadoop-env, hadoop-log4j, hdfs-site, httpfs-env, https-site, mapred-env, mapred-site, yarn-env, yarn-site, hive-env, hive-exec-log4j, hive-log4j, hive-site, pig-properties, pig-log4j.

Finally, on this page the optional step-based functionality is available. Here it defaults to waiting, which will keep the cluster running. So if using this method, make sure to select auto-termination in the upcoming 'Auto-termination' section.
The uniform instance groups and networking defaults should work, if there are hardware types wanted to be used in a templated fashion the fleets are better options. Also, if the VPC and security groups are not selected by default, they can be selected.

Next you can physically choose what node types will be provisioned, the defaults should work fine, but for larger workloads these settings are the first to be changed (in Spark's case adding more RAM) also spot versus on demand instances. On-demand are automatically provisioned and are more expensive, while spot instances are shared or excess so there is no guarantee there will be any available when requesting so your job can be delayed.
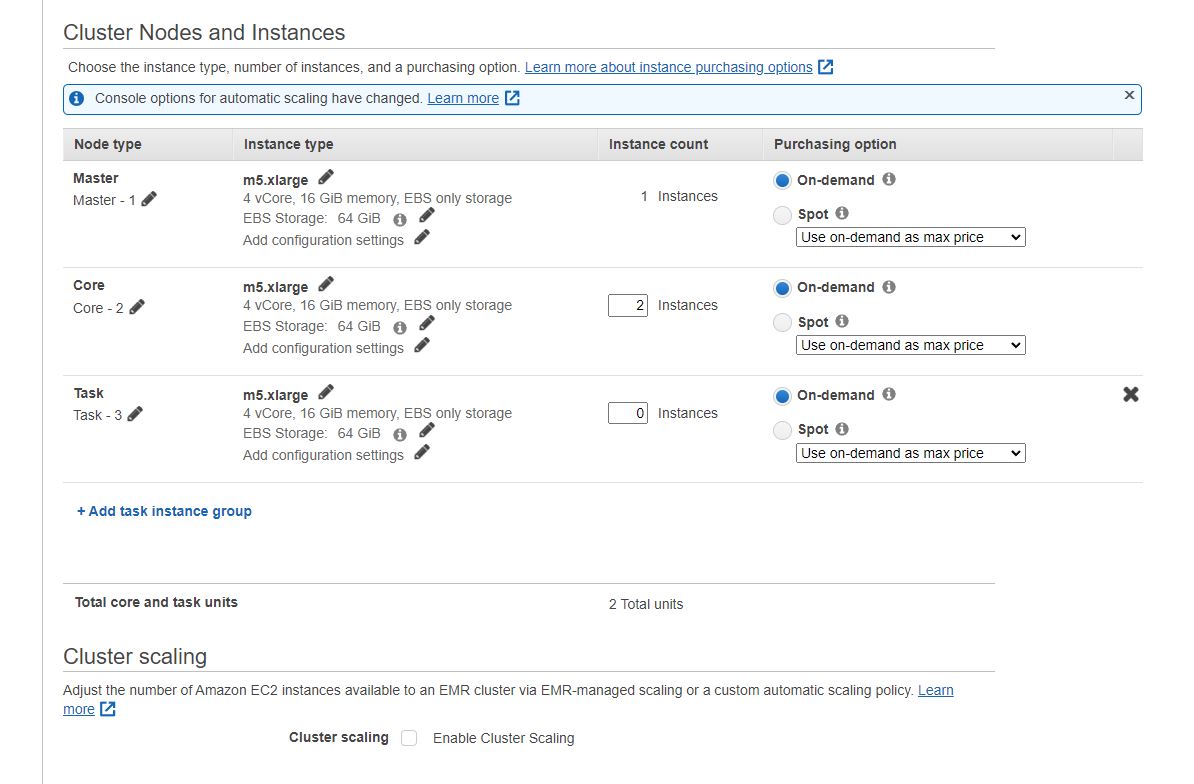
Next are the auto termination and root volume settings. The EBS volume is similar to SAN disk storage. For Spark, this value is fine as most of Spark disk access is ephemeral.
Here the S3 bucket for the cluster is selected, as well as some ancillary AWS options that are not necessary for running EMR, but help track instances within the AWS ecosystem.
The advanced security settings allow for individual security groups and deeper levels of configuration, but match the quick configuration. The biggest take away is that without a Key Pair SSH/terminal access to the physical Spark cluster will be impossible. So if this is a wanted access pattern, be sure to generate this prior.
Now press 'Create cluster' and the Spark Cluster is up and running!
Interacting With AWS EMR Using Notebooks
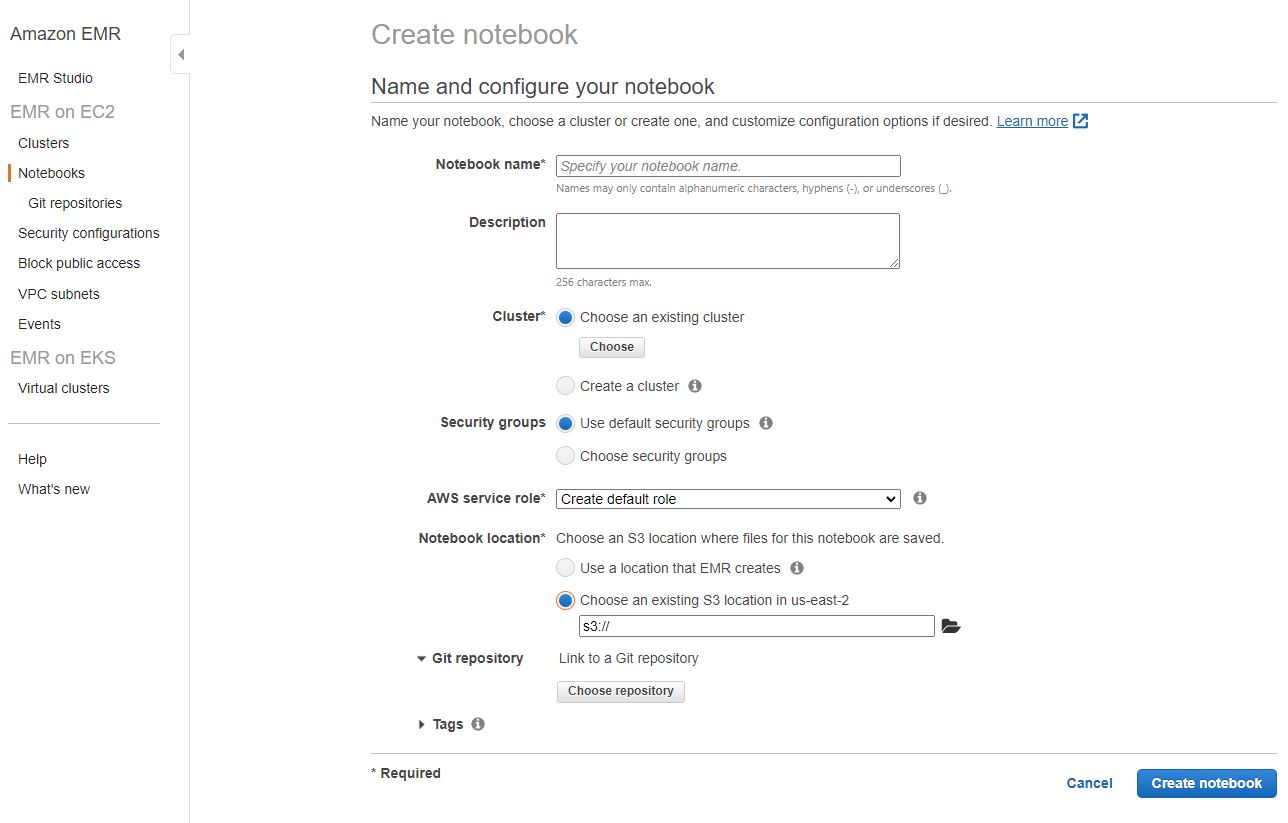
Once you made your EMR cluster, the easiest way to interact with it is through managed jupyter notebooks. To spin one up, go to the 'Notebooks' tab and the 'Create notebook' button. The screen shown below is all that is needed.
Notebook environments only work on EMR releases 5.18.0 and later. Further details on best practices for EMR cluster configurations optimized for Jupyter are listed on this page from AWS.
You just have to pick your cluster and security group, and it will create the other resources for you. You can also associate a git repo from this screen as well. Once this is spun up, an Anaconda-like interface will be available and make your Spark coding process immensely easier, integrating natively with AWS services and S3 buckets for easier I/O of data outside of EMR.
Expert Help
Admittingly, Zuar doesn't focus on EMR-type data processing. But if you are interested in EMR, chances are that you serve in a role where our products and services can help you.
- Get the most out of your data without hiring an entire team to make it happen. Learn about Zuar's data services for migration, integrations, pipelines, infrastructure, and models.
- Pulling data into a single destination and normalizing that data, whether in the cloud or OnPrem, can be difficult for any organization. Zuar's Runner solution provides comprehensive ELT and automated pipeline functionality without the learning curve and cost of many other solutions. You can learn more here.
- For Tableau customers, we've developed the Zuar Portal which spins up in under an hour. Provide your staff and 3rd parties secure offsite access without needing a VPN!


