This guide will discuss the loading of sample data from an Amazon Simple Storage Service (Amazon S3) bucket into Redshift. We’ll cover using the COPY command to load tables in both singular and multiple files. Additionally, we’ll discuss some options available with COPY that allow the user to handle various delimiters, NULL data types, and other data characteristics.
Files can be loaded into Redshift using INSERT or COPY. The latter is recommended by Amazon and is both faster and more efficient than INSERT. COPY leverages Redshift massively parallel processing (MPP) architecture while INSERT does not. Hence, we will exclusively cover COPY.
For this tutorial, we’ll be using the Redshift Query Editor, but any SQL IDE with a Redshift connection and sufficient permissions will work. The editor can be accessed through your Amazon Redshift dashboard on the left-hand menu.

Using the COPY Command
Assuming data is loaded into an S3 bucket, the first step to importing to Redshift is to create the appropriate tables and specify data types. In this example, we’ll be using sample data provided by Amazon, which can be downloaded here. We’ll only be loading the part, supplier, and customer tables. To create the tables:

Using a Key Prefix
Now that the tables are present in Redshift, we can begin loading them. The Redshift COPY command is formatted as follows:
COPY TABLE FROM 's3://<your-bucket-name>/<path-to-directory>/<key-prefix>’
CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
OPTIONS;
We have our data loaded into a bucket s3://redshift-copy-tutorial/. Our source data is in the /load/ folder making the S3 URI s3://redshift-copy-tutorial/load. The key prefix specified in the first line of the command pertains to tables with multiple files. Credential variables can be accessed through AWS security settings. For a detailed walkthrough, see the AWS docs.
Our first table, part, contains multiple files:

Using the key prefix variable, we can load these files in parallel using:
COPY part FROM 's3://redshift-copy-tutorial/load/part-csv.tbl’
The location 's3://redshift-copy-tutorial/load/part-csv.tbl’ will select each of the corresponding files, processing the table components into our table. Thus, key prefix acts as a wildcard when selecting tables. So, to load multiple files pertaining to the same table, the naming structure should be consistent or a manifest should be used. We’ll discuss loading tables with a manifest later.
Of course, if your table consists of a singular file, key prefix will also function as a file name. For example, if we only had part-csv.tbl-001, we could pass the S3 URI 's3://redshift-copy-tutorial/load/part-csv.tbl-001’ and only that file would be loaded.
One nuance for the part dataset is that NULL values do not correspond to Redshift’s accepted format— the part files use the NULL terminator character (\x000 or \x0) to indicate NULL values. We can account for this by passing the option NULL as '\000'. We also have to pass csv to denote the data format. The final COPY statement looks like:
COPY part FROM 's3://redshift-copy-tutorial/load/part-csv.tbl’
CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV
NULL as ‘\000’;
This takes our raw table in S3, scans the multiple files in parallel, accounts for NULL formatting, and outputs the end-result to the part table we created. For a complete list of options and parameters to pass to COPY, see this Amazon documentation.
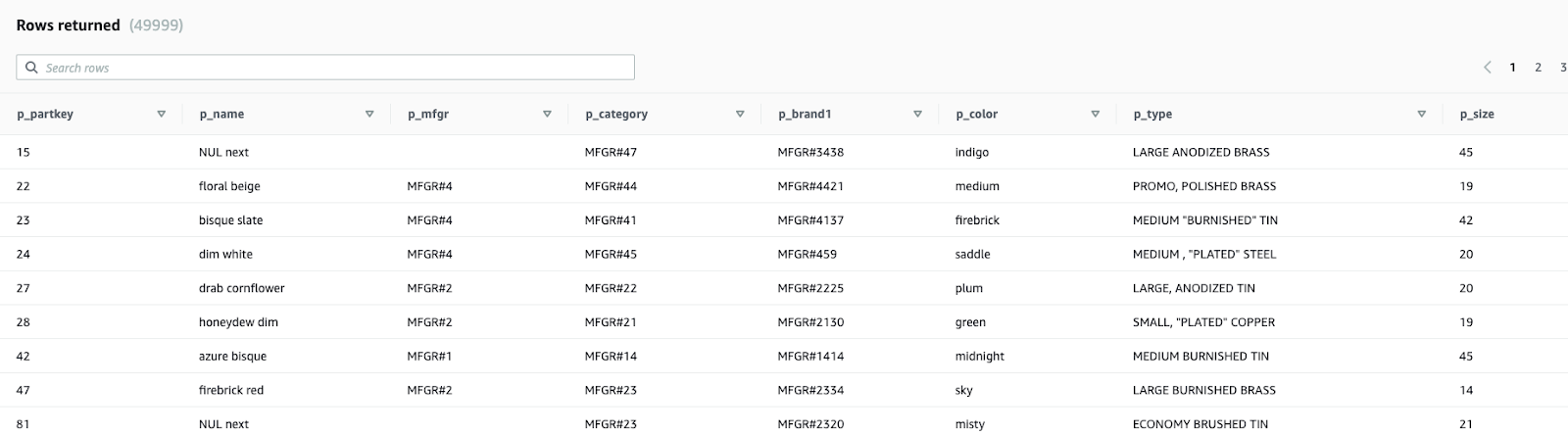
We can confirm the table was loaded with SELECT * FROM part:
Selecting From an External Bucket
Next, we’ll copy into the supplier table, it differs in a few ways:
- It’s hosted on one of Amazon’s public S3 buckets.
- The table is pipe-delimited.
- The files are compressed using GZIP, a popular data-compression method.
Since the data is on another bucket, we’ll need to select from that location instead and specify the region where it’s stored. We’ll also need to tell Redshift about the delimiter and compression method. The DELIMITER, MANIFEST, and REGION options convey this info. The final query would look something like:
COPY supplier FROM 's3://awssampledb/ssbgz/supplier.tbl'
CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
DELIMITER '|'
GZIP
REGION 'us-east-1';
Note the bucket name and file path, which will not change— we’re fetching data from a sample Amazon bucket and loading it into our Redshift cluster. This is possible because Amazon’s bucket is public.
Using a Manifest File
Lastly, we’ll copy in the customer table using a manifest file. Manifest files are important for specifying precisely which tables to load. In our part table example, imagine we only wanted to load the first 5 partial tables— we couldn’t do that using a key prefix since all files would be selected, but we could with a manifest. In this case, we’ll want to exclude the “.bak” and “.log” files from being loaded.
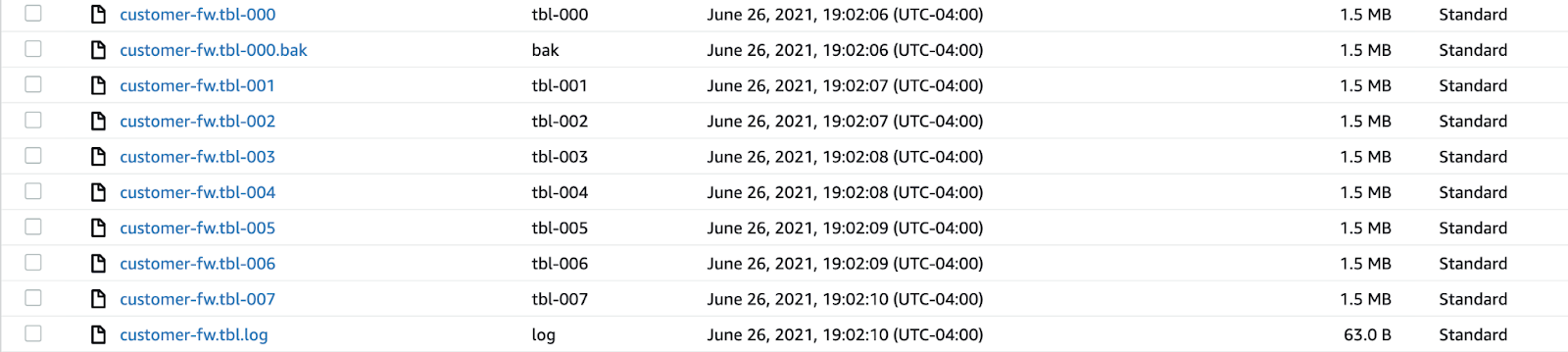
We’ll create a manifest file and input the S3 URI of the table files in the following JSON format:
{
"entries": [
{"url":"s3://redshift-copy-tutorial/load/customer-fw.tbl-000"},
{"url":"s3://redshift-copy-tutorial/load/customer-fw.tbl-001"},
{"url":"s3://redshift-copy-tutorial/load/customer-fw.tbl-002"},
{"url":"s3://redshift-copy-tutorial/load/customer-fw.tbl-003"},
{"url":"s3://redshift-copy-tutorial/load/customer-fw.tbl-004"},
{"url":"s3://redshift-copy-tutorial/load/customer-fw.tbl-005"},
{"url":"s3://redshift-copy-tutorial/load/customer-fw.tbl-006"},
{"url":"s3://redshift-copy-tutorial/load/customer-fw.tbl-007"}
]
}
That file will then be uploaded to our S3 bucket with the name customer-fw-manifest. Now, we can specify the COPY command as before and load this table in parallel. Note that a manifest file must be created outside of AWS and uploaded to the appropriate path within a bucket.
Some other important characteristics for this data are: FIXEDWIDTH, MAXERROR, ACCEPTINVCHARS, and MANIFEST.
FIXEDWIDTH defines each field as a fixed number of characters, rather than separating fields with a delimiter. MAXERROR instructs COPY to skip a specified number of errors before failing— this particular table is built with errors. ACCEPTINVCHARS replaces invalid characters (which are present in the dataset) with a character of our choice. Here, we use ‘^’. Finally, we specify MANIFEST to denote we’re loading a manifest file. These are necessary transformations for this dataset and are provided as examples of possible load configurations. Again, Amazon documentation provides elaboration on each of these options and more.
COPY customer FROM 's3://redshift-copy-tutorial/load/customer-fw-manifest'
CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
FIXEDWIDTH 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10'
MAXERROR 10
ACCEPTINVCHARS as '^'
MANIFEST;
With the manifest method, any combination of table parts can be loaded by specifying each S3 URI.
Beyond COPY
In this tutorial, we’ve demonstrated how to load several table types from Amazon S3 to Redshift using COPY. Leveraging parallel processing, COPY is the fastest and most efficient way to load data from S3.
If you need to bring in data from other sources, a robust ELT platform such as Zuar Runner is a powerful solution. Beyond pulling data from a wide selection of sources, Runner will normalize the data and leave it fully prepared for analysis.
Visit here for more information about Zuar Runner.



