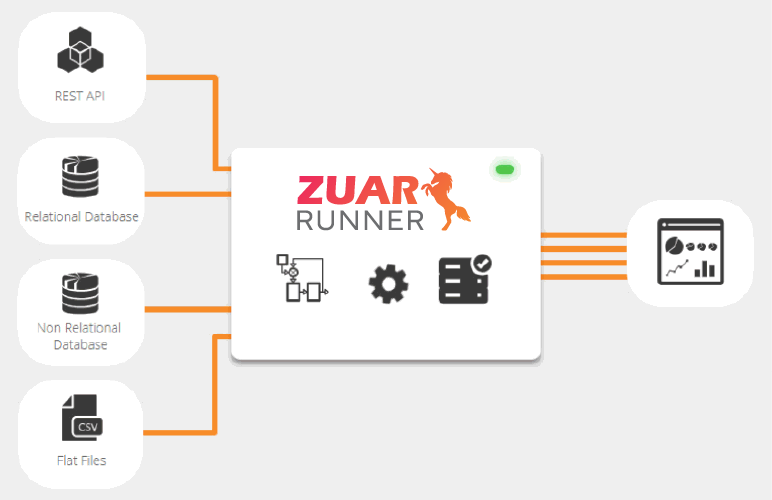
What is a data pipeline?
Data pipelines are systems that pull in data points from different sources and consolidate them into a streamlined repository for analysis and modeling. Your data pipeline could be handling thousands of data points from multiple sources, depending on your company's scope. Beyond that, the data itself may be of varying types (qualitative vs. quantitative, for example), and analytics dependent on that data is at the mercy of the quality of your data pipeline architecture.
See also HOW to build a data pipeline.
A data pipeline is a predominantly automated process, and running jobs through it involves an intricate series of extraction, preparation, and analysis. If you decide to make your pipeline, accounting for each step of data consolidation is the key to success and continued efficiency.
Each situation is different, but a common method used by companies to create their pipeline is to script the system themselves. While this procedure offers more control over the flow of data, it comes with specific challenges, namely:
- Constant maintenance
- Time-consuming integration during updating
- Diminishing data quality if done incorrectly
- Worse, possible data loss
When deciding whether or not to create an in-house data pipeline, it is essential to consider these drawbacks. Don’t get us wrong, there are numerous benefits towards having more control over where your data is flowing, and how you present it. But executing this process efficiently can be a challenge.
Related:

Why is building data pipelines difficult?
Besides the fact that data is continuously being collected and consolidated, maintaining a pipeline provides unforeseen drawbacks that can affect the speed of your operations. By examining industry leaders, we’ve found that the most common issues in pipeline development come from the problems in practicality.
Related

Cost
Designing a pipeline is not a one-shot deal. You will always be expanding your pipeline as your enterprise's scope grows, which is a natural part of owning a business that relies heavily on analytics. Constantly integrating numerous REST APIs can end up costing money in the time needed to troubleshoot and test; personnel to consistently adjust the network also accrue added costs.
Auditing
When expanding your business, it is vital to keep the data you collect clean for auditing purposes. Reducing noise in the data collection process is only part of the solution; the other part is designing a pipeline that is able to adapt to handling newly-introduced endpoints in the system. The reproducibility of your data is critical, but this is only possible by maintaining a flexible data pipeline. Say, for instance, you have a collaborator who wants to run post hoc analyses on a data set your team collected, but they want to debug your code; let’s say they want to change variable types. A flexible data pipeline will allow for these instances to happen, but if not done with care, debugging can take hours.

Consistency
When you call a job with a specific analysis plan in mind, you depend on the data remaining consistent. When adding new properties, as is typical when expanding your own data pipeline, you risk altering the data in ways that can pose problems for further analyses. For example, something as simple as changing the variable type can cause significant losses in time and money.
Beyond these clear problems with maintaining a data pipeline, simply building them can wreck your team’s morale -- think about it this way: say your organization is thinking of adding three new pipelines due to expansion. Depending on the complexity of the data set, how the data set will be leveraged by analytics, as well as how thoroughly the data needs to be cleaned, each individual pipeline would need a dedicated personnel (e.g., data engineer, dba, data scientist, etc.) to oversee, implement, and test. These individuals could very well be operating other sectors of your company, and it’s unrealistic to expect that their other tasks be pushed aside completely while implementing a new data pipeline.
Again, this depends strongly on the amount of control you would like over the pipeline, and how many resources are at your disposal to build one with your team.
Are you looking for remedies to your data pipeline bugs? Connect with Zuar for your data science questions! Schedule a data strategy assessment.
It's here that you need to start asking the harder questions:
Can my team handle scaling the data pipeline as we grow?
This feeds back into the issues of growth of your company. You will soon go from only handling maybe a few thousands of cells, to handling millions of data points of varying types. The ability to expand efficiently without drops in quality is desirable, no matter how small or large your current operations are.
Do I have the resources to constantly monitor failures and bugs in my pipeline?
Failures in the system will inevitably happen. As you integrate new SaaS directories and have to deal with each individual API headaches, much of your monitoring tasks will be delegated towards detecting and fixing bugs in your pipeline. They may be as minor as a license expiring, to as major as entire data repositories being killed. Being vigilant and generating queries on a consistent basis is no small feat, and requires a good amount of time and cleaning.
Will the system I design remain as flexible as a third-party service?
This here is probably the most important aspect of a pipeline; how flexible is it? Will integrating new destinations or functions take hours, days, weeks? Will the ETL process interface well enough with things outside of your control like web APIs? These are all aspects of a flexible system that many groups simply cannot reasonably monitor. Moreover, if you end up using a cloud-based data manager, you need to worry about added security.
Thankfully, Zuar is well-equipped to assist in optimizing your business efficiency and data strategy. We recognize that constant growth means upscaling and reassessing your legacy systems, and we know how to target issues in data piping with intelligent precision.
Are you ready to revolutionize your pipeline and discover smart solutions for your data analytics strategy? Schedule a data strategy assessment!