Data lakes, mesh, & fabric are three intertwined concepts that evolved from the traditional data warehouse:
1) Data lakes attempt to improve flexibility by leveraging cheap storage costs afforded by advancements in cloud storage technology. The guiding principle behind a data lake is that all raw data is captured and stored centrally, where it can then be ingested by a data warehouse or analyzed at scale.
2) Data mesh is a framework for organizing and disseminating data within an organization. Data mesh is built on treating data as a product and creating individual areas of ownership for relevant subject matter experts (SMEs). Through this federated approach, data mesh seeks to reduce data sprawl and increase ownership.
3) Data fabric attempts to solve similar problems to data mesh, albeit through a technical framework rather than an organizational one. This is achieved through maintaining a centralized datastore and requiring strict access protocols. By implementing a rigorous, unified technological approach, data fabric attempts to make data possible at scale.

Introduction
The modern data warehouse is a concept that’s developed over the past decade to describe a central data management system that leverages data from different arms of an organization to support business intelligence and analytic efforts. With the proliferation of cloud technology, fully-hosted columnar warehousing solutions have never been easier to manage. Now, many are opting for data lakes, which build on traditional warehouses and offer additional flexibility in data modeling.
As data technology has evolved, the approaches to a sustainable data solution have bifurcated into a plethora of approaches. This has led to a confusing mess of buzzwords and dense terminology. In this article, we’ll discuss the difference between a data lake, data fabric, and data mesh with the hope of clearing up some ambiguity.
We’ll also tie all three back to our concept of a modern data warehouse, illustrating the evolution of these terms and data practice at scale.


The Modern Data Warehouse
Before understanding derivative technology, it’s necessary to have a grasp on data warehouses. Since the invention of the database, data warehouses have been used to store data in a format ideal for analytic purposes (queries and BI). Historically, this was by necessity, since storage was on-prem (physical) and extremely limited.
However, data warehouses have undergone a transformation in only the past few years. Companies like Google (BigQuery) and Amazon (Redshift) have introduced flexible cloud warehousing solutions. The competition in this space has resulted in highly refined products whose cost and complexity continues to fall.
These performant warehousing solutions have been at the core of a renaissance in data technologies, from BI to metadata tracking. The modern data stack is now about more than storing analytic data— it’s about understanding data origins, tracking lineage, managing access and permissions, and maintaining flexibility in modeling.

Data Lake
A Data Lake is a single store for all data—whether it be raw, unstructured, semi-structured, etc. This data is taken from multiple sources and lacking a predefined schema. The idea is that a central repository holds every bit of this raw data, which can then be leveraged for downstream data needs.
Data lakes have a tremendous amount of flexibility, since they retain all data that may have value. By storing all of this information, downstream processes can be altered and manipulated without fear of data loss— for example, a refactor of an ELT pipeline in SQL that queues off a data lake can change to accommodate business needs.
At the same time, data that’s inappropriate for a warehouse (either due to size or structure) could be analyzed through machine learning or other data science techniques.
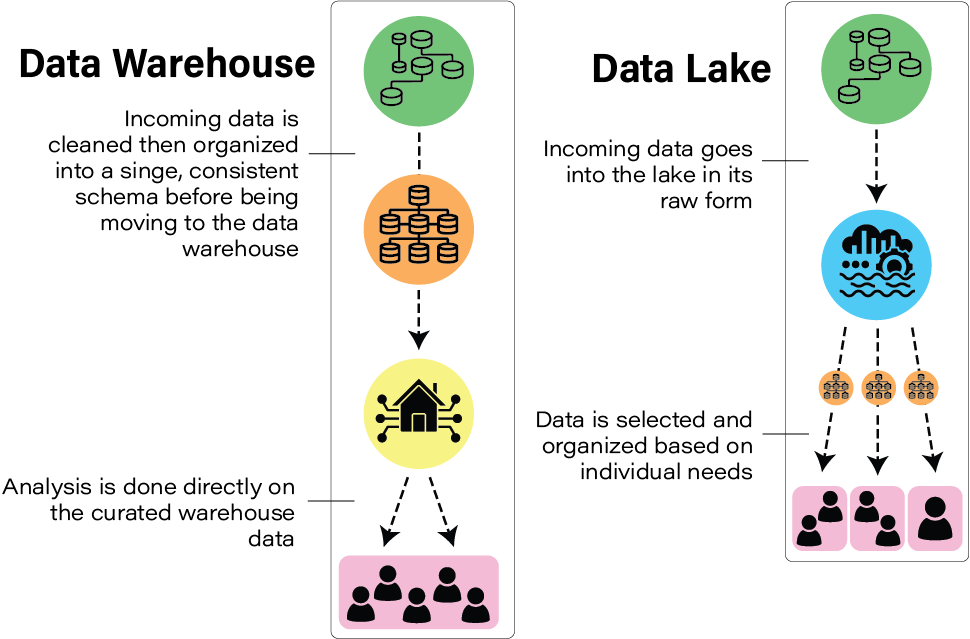
Data lakes evolved from data warehouses and cloud data storage. As the storage costs with major cloud providers have plummeted, it’s become fiscally possible to simply store everything and worry about analyzing it later. With increased flexibility and control around cloud computing power, processing services can be scaled up/down to meet business needs.
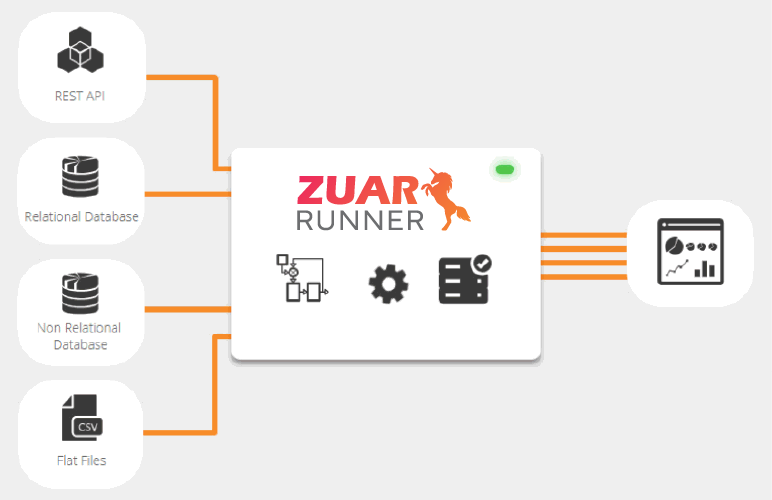
This addresses the biggest weakness of Extract, Transform, Load (ETL) processes—if data is transformed before storage, information will be lost. Advancements in cloud computing and storage have driven evolutions in data tooling and best practices. Learn how Zuar's data ELT solution, Zuar Runner, also helps to overcome these challenges:


Data Mesh
The data mesh framework (established by ThoughtWorks) seeks to create a foundation for deriving value from analytical data and historical facts at scale. This is accomplished through its core tenets: treating data as a product, providing self-serve data infrastructure, and taking ownership of all things contained within the data org— from pipelines to governance.
The data mesh concept addresses limitations of top-down data management, suggesting that the appropriate subject matter expert (SME) should own and manage pertinent data from start to finish. This bottom-up approach is designed to improve data accountability and avoid warehouse sprawl.
A potential flaw: if improperly managed, data meshes could accelerate data silos and create repetitive datasets. By having SMEs operate independently, a data mesh could evolve to be disparate, fragmented, and incongruent. Thus, it’s necessary to have a supportive organizational structure around these federated SMEs to establish incentives and architecture to ensure cohesive development.
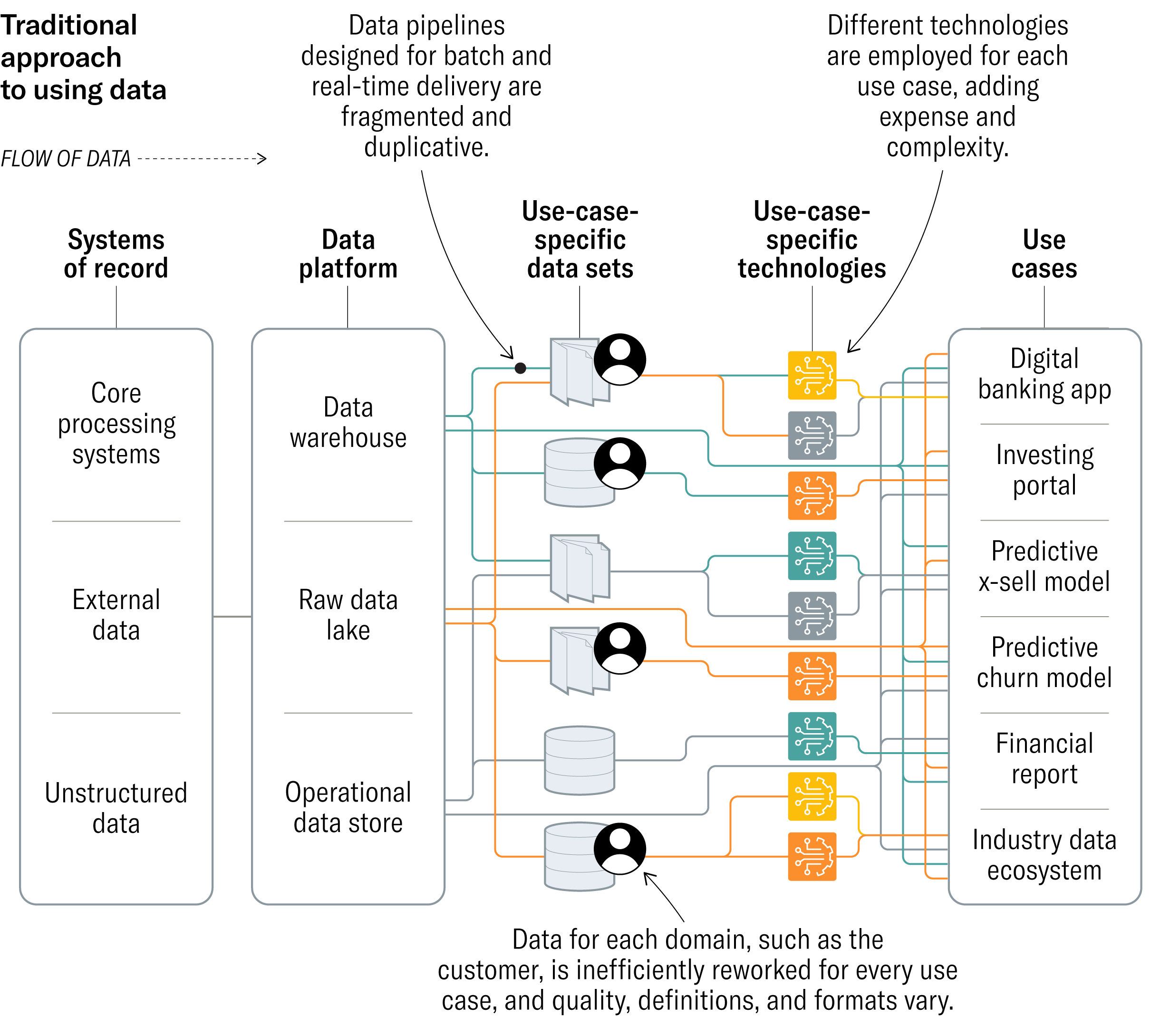
Data mesh is yet another extension of the modern data warehouse. At the heart of a data mesh is a lake or warehouse, the “mesh” concept is more of a framework used to establish ownership over data through a product lens. This concept has evolved as many companies realize prevailing data architectures can lead to fragmented, duplicative data stores that generate more confusion than insight.

Data Fabric
Data fabric also builds on the concept of a modern data warehouse by incorporating data access and policy, metadata catalog/lineage, master data management, real-time processing, and additional tooling/services/APIs.
An observant reader might notice that this sounds eerily similar to a data mesh— this is accurate. Both are concepts for accessing data across a multitude of technologies, hence the need for articles like these. However, the two differ in a fundamental way: data fabric is a technology-centric solution, while data mesh focuses on organizational frameworks.
The data fabric solution is also not as distributed as its data mesh counterpart. In a data fabric, a centralized store for data is created. Data is pulled from this repository for downstream purposes. At its core, data fabric is about collecting data and making it available via APIs or direct connection. This is the technical piece that defines a data fabric which is absent from data mesh.
An example: a business user needs a dashboard that measures product engagement and conversion. In a data fabric, I would ingest sales data (conversion) and product data (engagement) in a central location, then build an API that joins them together and expose that API to a dashboard.
While both are unified approaches to managing organizational data at scale, data mesh leverages a decentralized framework and organizational structure, while data fabric opts for a strict technical implementation.
It’s also very important to note that both of these technologies are evolving. The principles of fabric/mesh were defined in the last year and there is no consensus on a “correct” implementation for either framework. As such, they should be treated as just that: frameworks. In their present state, data mesh and fabric are useful concepts for those working to architect a data organization, but neither are concrete solutions.

Implementing
A quickly evolving data landscape means that these concepts are not fully defined. New technologies continue to be developed and adopted as data practitioners explore the best ways to build data driven organizations at scale. The best solution is the one that makes the most sense for your team.
Navigating the creation of data lakes/mesh/fabric can be an arduous task, but that's where Zuar comes in.

Our services team will meet with you to learn about your data needs, and help you formulate a data strategy. You can also learn how our ELT solution, Zuar Runner, can help you seamlessly connect your data lake/mesh/fabric to hundreds of other potential sources.
