
Last Updated: July 7, 2026
What Is GCP Dataflow?
GCP Dataflow is a managed service on Google Cloud Platform that allows for efficient processing of batch and streaming data, providing a serverless environment for executing Apache Beam pipelines.
With its serverless architecture and integration with Apache Beam, Dataflow provides developers and data scientists with a robust platform to process both batch and streaming data, reducing operational overhead and accelerating insights delivery.
Whether it's transforming large volumes of historical data or analyzing real-time streams, Dataflow empowers organizations to unlock the full potential of their data while leveraging the scalability and reliability of the cloud.
Key Takeaways
- GCP Dataflow provides serverless, scalable data processing using Apache Beam and other GCP services like BigQuery and Pub/Sub.
- Dataflow reduces operational overhead but is limited by Apache Beam's capabilities and locks users into Google's ecosystem.
- Potential customers should evaluate if Beam and GCP meet their data processing needs compared to more flexible, platform-agnostic alternatives. Alternative solutions like Zuar's Data Experience Platform offer fixed pricing, cross-platform flexibility, and end-to-end data pipeline automation with analytics delivery.
Background on GCP Dataflow
GCP Dataflow is a managed service used to execute Apache Beam data processing pipelines using the Google Cloud Platform (GCP) ecosystem.
For our purposes, data processing refers to the procedure of taking large amounts of data, potentially combining it with other data, and ending with an enriched dataset of similar size or a smaller summary dataset. A pipeline is a sequence of steps that reads, transforms, and writes data.
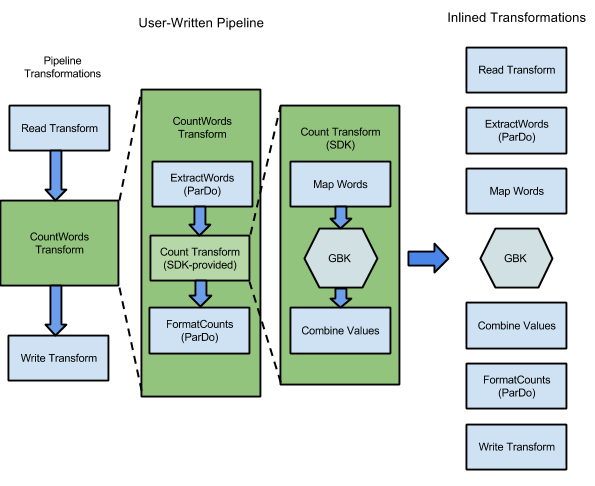
Apache Beam is a framework with bindings in Python and Java that enables simple representation of data processing pipelines.
Beam is built around the concept of PCollections (parallel collections) and Transforms on those collections. Together, PCollections and Transforms form Apache Beam Pipelines.
Beam is based on an internal model at Google, which evolved from MapReduce and successors like Flume & MillWheel. The Beam model represents all datasets uniformly via PCollections.
A PCollection could be in-memory, read from Cloud Storage, queried from BigQuery, or read as a stream from a Pub/Sub topic.
Dataflow primarily functions as a fully managed pipeline runner for Apache Beam. Dataflow was released in April 2015. Dataflow supports:
- Bounded (static size) and unbounded (streaming) data
- Integration with BigQuery, Cloud Storage, and Pub/Sub
For organizations seeking alternatives to Google-locked infrastructure, modern data pipeline platforms like Zuar DXP provide similar automation capabilities across multiple cloud providers without vendor lock-in.
In January 2016, Google donated the underlying SDK and a few other components to the Apache Software Foundation. The donated code formed the basis for the Apache Beam project, hence the close connection to Dataflow.
The Beam documentation provides conceptual information and reference material for its programming model, SKDs, and other runners.

Why Use GCP Dataflow?
Now that we understand the relationship between Beam and Dataflow, we can discuss Dataflow functionality.
Dataflow is an expansive system designed to make data and analytics more accessible using parallel processing. It has a board range of use-cases including:
- Data integration and preparation (e.g. preparing data for interactive SQL in BigQuery),
- Examining a real-time stream of events for significant patterns,
- Implementing advanced processing pipelines to extract insights.
Cloud Dataflow requires no initial setup of underlying resources: it’s a fully managed tool. Because Dataflow is fully integrated with the Google Cloud Platform (GCP), it can easily combine services we’ve discussed in other articles, like Google BigQuery.
GCP Dataflow Concepts
PCollections
A PCollection is the canonical representation of 'data' in a pipeline. Every step in a pipeline takes and/or returns a PCollection object.
PCollections can hold any type of object—integers, strings, composite objects, table rows, etc. without any size restrictions. There are two types of PCollections
- Bounded PCollections hold datasets of limited and known size that do not change. For example, data sources and sinks for the classes TextIO, BigQueryIO, and DatastoreIO, and those created using the custom source/sink API are Bounded PCollections.
- Unbounded PCollections are representations of data that are continuously added, i.e. there are no boundaries to the dataset. PubSubIO works with unbounded PCollections on the source and sink sides. BigQueryIO accepts unbounded PCollections as sink information.
Since Unbounded PCollections can contain an unlimited amount of data, interruption points must be defined to allow Dataflow to work on finite chunks of transformed information.
Transforms
Transforms represent each step taken to mutate data from the original source to a modified state. Transforms primarily occur on PCollections. PTransform objects implement the apply method, which is where transformations are applied in Apache Beam.
Dataform best practices dictate breaking down Transforms into chunks of logic that can be grouped together. This improves code readability, testability, and reusability.
Dataform allows for viewing pipelines as a Directed Acyclic Graph (DAG) and building discrete Transforms aids in a digestible visual representation of a data pipeline.
ParDo
ParDo is one of the core transformations for parallel computing in Dataform. It applies logic specified via a function class (DoFn) to each element in a PCollection. ParDo can accept multiple input data through side inputs & return multiple output PCollections.
GroupByKey
GroupByKey allows for grouping key-value pair collections in parallel by their key. GroupByKey is often useful in one-to-many datasets that should be grouped by key—it returns a collection of pairs with unique keys holding multiple values.
Combine
Combine aggregates a collection of values into a single value or key-value pairs into key 'grouped' collections. The transformation also accepts a function class that can be used to aggregate a collection.
Flatten
Flatten is a common transformation for merging a list of PCollection objects (of the same type) into a single PCollection.

Data Sources & Sinks for GCP Dataflow
Data pipelines read from a data source and write to a sink. Cloud Dataflow makes it simple to treat many sources/sinks similarly by providing a set of representative interfaces, allowing for flexible information processing.
Sources generate PCollections and sinks accept them as input during a write operation. Here are some common Dataflow sources and sinks:
- Cloud Storage Datasets: Cloud Dataflow can accept and write to Google Cloud Storage (GCS) datasets. The tight integration with other GCP resources is one of Dataflow’s biggest strengths.
- BigQuery Tables: The BigQueryIO class allows for interaction with Google BigQuery for reading and writing data. BigQuery can be a useful sink if further aggregation or analysis is required on data.
- Google Cloud Pub/Sub Messages: While only available for streaming pipelines, Dataflow can read from and write data to Cloud Pub/Sub messages with the PubSubIO class. Pub/Sub is very powerful for real-time data consumption.

Additional Functionality of GCP Dataflow
Vertical Autoscaling
Dataflow adjusts the worker compute capacity based on utilization. Combined with horizontal autoscaling, this can seamlessly scale workers to best fit a pipeline.
Vertical autoscaling makes jobs resilient to out-of-memory errors, maximizing pipeline efficiency. Vertical autoscaling is a part of the Dataflow Prime service.
Horizontal Autoscaling
Horizontal autoscaling automatically selects the appropriate number of worker instances required to run a data job. Dataflow may also dynamically re-allocate more or fewer workers during runtime.
Given that a pipeline may vary in computational intensity, Dataflow may automatically spin-up/shut down workers during different phases to optimize resource usage.
Dynamic Work Rebalancing
Dataflow’s Dynamic Work Rebalancing allows for dynamically re-partition work based on runtime conditions, including:
- Imbalances in work assignments
- Workers taking longer than expected to finish
- Workers finishing faster than expected
The Dataflow service automatically detects these conditions and can dynamically reassign work to unused or underused workers to decrease your job's overall processing time.
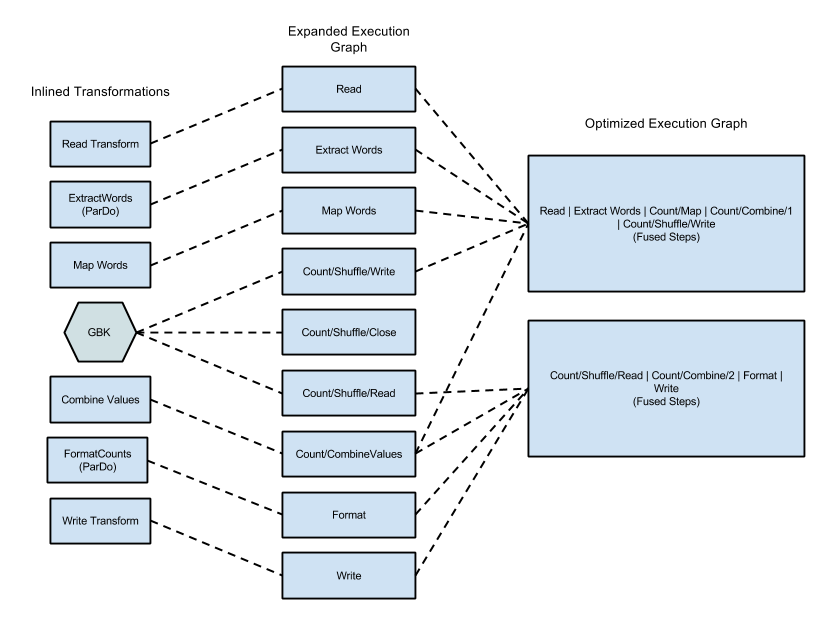
Fusion Optimization
Once the JSON form of your pipeline's execution graph has been validated, the Dataflow service may modify the graph to perform optimizations. Such optimizations can include fusing multiple steps or transforms in your pipeline's execution graph into single steps.
Fusing steps prevents the Dataflow service from needing to materialize every intermediate PCollection in your pipeline, which can be costly in terms of memory and processing overhead.
While all the transforms you've specified in your pipeline construction are executed on the service, they may be executed in a different order, or as part of a larger fused transform to ensure the most efficient execution of your pipeline.
The Dataflow service respects data dependencies between the steps in the execution graph, but otherwise steps may be executed in any order.
Dataflow SQL
Dataflow supports SQL to allow development of streaming pipelines directly from the BigQuery web UI.
Streaming data from Pub/Sub may be joined with files in Google Cloud Storage or tables in BigQuery, results may be written to tables in BigQuery, and real-time dashboards may even be built with Google Sheets or another BI tool by leveraging Dataflow SQL.
Notebook Integration
Pipelines may be built on top of Vertex AI Notebooks and deployed with the Dataflow runner. All the benefits of notebook based development are available: an intuitive environment, fast debugging, and live interactions with code.
Notebooks in Dataflow allow engineers to leverage the latest data science and machine learning frameworks in a familiar setting.
Real-Time Change Data Capture (CDC)
Using Dataflow, data professionals can synchronize and replicate data reliably and with minimal latency to drive streaming analytics.
A library of Dataflow templates integrate with Google Datastream, which allows for replication of data from Cloud Storage into BigQuery, PostgreSQL, or Cloud Spanner.
Organizations seeking CDC capabilities across multiple cloud platforms and databases often turn to platform-agnostic data orchestration tools like Zuar DXP that support diverse source and destination systems beyond the Google ecosystem.

Limitations of GCP Dataflow
Usage Limits
Dataflow is governed by a number of quotas, though some may be overcome by contacting Google Cloud Support (the concurrent jobs limit is a good example).
Community & Support
Many data professionals know that support for a product is essential, especially when business-critical data is being processed. From cursory research, it appears that Google Cloud Support is hit-or-miss. Many users have reported lackluster experiences:
Similarly, potential customers should evaluate community support for GCP and Dataflow. While the Beam project is open source, it’s important to consider if other data professionals are vetting the product and discussing technical issues on forums, etc.
Programming Model
Dataflow is built on the Apache Beam programming model. As such, usage of Dataflow is limited by the suitability of Apache Beam for any particular job.
In a market with hundreds of data processing frameworks, it’s necessary to spend adequate time evaluating all competitors to ensure an optimal solution.
Cost
Cloud Dataflow service usage is billed in per second increments on a per job basis. Cost depends on factors including:
- Dataflow Worker type
- vCPU (per hour)
- Memory (per GB per hour)
- Data processed during shuffle
Google offers a pricing calculator to assist in estimating cost, but due to the high number of variables, Dataflow cost will be specific to any particular use case.
As such, any Dataflow user should be aware of the potential cost fluctuations of a pipeline. Jobs should be audited to ensure reasonable resource usage.
As with any data platform, other providers may be more cost effective depending on use-case, billing agreements, and other factors. For example, Zuar's Runner pipeline platform is provided with completely fixed pricing, eliminating billing surprises.
Platform Specific
While some may find it to be a pro, it’s important to note that Dataflow is a part of the Google Cloud Platform. It will not work with AWS, Azure, Digital Ocean, etc. That's why many companies opt for solutions that are platform agnostic.
Much of the benefit from GCP comes from the fully-integrated nature of Google’s products. Using Dataflow with Cloud Pub/Sub, Cloud Storage, and Google BigQuery presents simplification over configuring and managing services from different providers.
Nonetheless, if required functionality is absent from GCP or if your use-case necessitates a different provider, Dataflow may not be an ideal solution.
Due to the complex nature of data processing, there is no one-size-fits-all approach. Potential customers should consider all aspects of GCP when making a purchase decision on Dataflow.
Platform lock-in may not be ideal if functionality gaps exist in GCP or use cases require multi-provider support. Modern Data Experience Platforms support lakehouse architectures like Databricks alongside traditional cloud data warehouses, providing flexibility across providers without vendor lock-in.

Considering GCP Dataflow?
GCP Dataflow is a powerful option for organizations deeply invested in Google Cloud, but it's important to evaluate:
- Fit between Apache Beam/Dataflow capabilities and your data needs — Does the programming model align with your team's skills and use cases?
- Willingness to adopt GCP's ecosystem and cost structure — Are you comfortable with per-second billing and potential cost volatility?
- Alternatives for platform-agnostic, fixed-cost pipelines — Do you need flexibility across cloud providers?
The Modern Alternative: End-to-End Data Experience
While GCP Dataflow excels at pipeline execution within the Google ecosystem, organizations increasingly need solutions that connect the full journey from data sources to pipelines to analytics to action.
Zuar's Data Experience Platform

Zuar Runner automates data ingestion, transformation, and preparation for analytics, supporting scalable ELT pipelines across cloud providers—including Google Cloud, AWS, Azure, and modern lakehouse platforms like Databricks—with fixed, predictable pricing.
Zuar Portal provides enriched and branded analytics delivery, creating powerful data experiences that combine dashboards, AI and workflow integration, even embedding and combining existing tools like Tableau, Power BI, and ThoughtSpot in white-label portals that serve both internal teams and external customers.
Together, Zuar's Data Experience Platform provides:
- Platform-agnostic flexibility — No vendor lock-in; works across cloud providers and BI ecosystems.
- Fixed pricing — Predictable costs vs. per-second billing variability
- End-to-end coverage — From data acquisition to analytics delivery and operational workflows
- AI-ready infrastructure — Conversational analytics with governance and row-level security, builder assistant agents, MCP tools and more.
- Expert implementation support — Zuar Labs ensures successful outcomes, not just software licenses
Modernize Without Rip-and-Replace
Zuar can embed your existing BI tools (Tableau, Power BI, ThoughtSpot) while providing the flexibility to evolve on your timeline. You control the pace of modernization—no forced disruption.
