
What Is Data Wrangling?
Data wrangling is the process of transforming raw, messy data into a structured, clean format that can be easily analyzed. This process is also referred to as data munging. It involves a range of tasks like data cleaning, data transformation, and data enrichment to prepare the data for downstream use.
Data wrangling is different from data cleaning in that it is a broader process that encompasses additional steps beyond just identifying and fixing issues in the data. While cleaning focuses on removing errors, wrangling aims to reshape and enhance the data.
Key Takeaways
- Data wrangling transforms raw, unstructured data into clean, structured formats to enable accurate analysis and impactful insights.
- It involves identifying data issues, cleaning, reshaping, and enriching data through techniques like fixing missing values, removing duplicates, standardizing formats, and joining data.
- Tools and services like Zuar help streamline the complex but crucial process of data wrangling.
Data Wrangling Tasks
Some common data wrangling tasks include:
- Identifying and removing duplicate records
- Fixing structural errors like misspelled column names
- Standardizing data formats like dates
- Handling missing values
- Merging multiple datasets
- Adding derived columns based on calculations
- Converting data types
- Anonymizing private data
- Filtering and sampling data
- Joining together data from various sources
The goal of wrangling is to take raw, unstructured data and transform it into a high-quality, analysis-ready dataset. This allows the data to be easily consumed and leveraged to draw insights.

Why Is Data Wrangling Important?
Data wrangling is a critical step in the data analysis pipeline. It involves preparing raw data for downstream analytics and machine learning tasks. There are several reasons why properly wrangling data is so important:
Prepare Data for Analysis
Real-world data is often incomplete, inconsistent, and contains errors. Techniques to wrangle data such as cleaning, structuring, and enhancing can transform messy data into high-quality data ready for analysis. Proper wrangling improves data quality and integrity before feeding it into models.
Improve Data Quality
Raw data frequently has issues like missing values, duplicates, outliers, and irrelevant observations. Identifying and fixing these problems through wrangling results in more accurate, consistent data for analysis. This leads to better insights and decisions.
Combine Data From Multiple Sources
In today's data-driven world, analysis often requires aggregating data from various internal and external sources. Data wrangling provides methods for merging, blending, and appending different datasets into unified data ready for modeling.
Transform Data Into a Useful Format
Algorithms and models require data in a specific shape and format. Data wrangling reshapes raw data into the structure and form required for particular data analytics techniques through pivoting, normalizing, aggregating, and filtering. This makes the data usable for analysis.
Proper data wrangling saves time and improves results by enabling higher-quality data pipelines. It is an essential step in maximizing the value extracted from data.

Benefits of Data Wrangling
Data wrangling provides several key benefits that make it a crucial step in the data analysis process:
Time Savings - While data wrangling takes time upfront, it saves significant time later in the analysis process. With clean, structured data, analysts don't have to spend as much time handling data issues during analysis. Data wrangling improves analysis efficiency.
More Accurate Analysis - Higher quality data leads to more accurate analysis. With properly wrangled data, models function better and analysts can avoid mistakes caused by data errors. Data wrangling helps ensure analysis reflects true relationships vs spurious correlations.
Uncover Insights - Data wrangling enables analysts to get the most value out of their data. Transforming data into the right shapes makes recognizing patterns easier. Fixing data quality exposes insights that may have been obscured before. Data wrangling helps unlock the full potential of data analysis.

Data Wrangling Steps
Data wrangling involves several key steps to turn raw data into usable, accurate information.
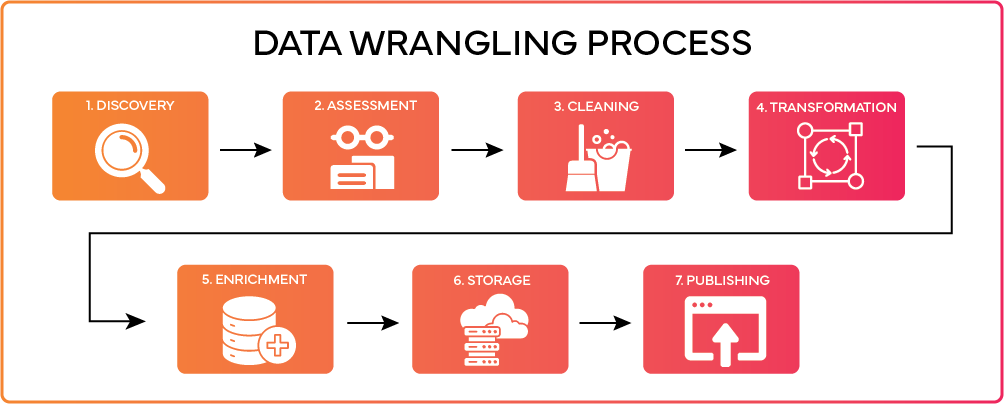
- Data Discovery - The first step is gathering data from various sources, whether databases, files, websites, sensors, social media, surveys, etc. The data collected can be structured, semi-structured, or unstructured.
- Data Assessment - Once data is collected, it needs to be assessed to understand the contents. This involves inspecting, profiling, and auditing the data to determine quality issues.
- Data Cleaning - Data cleaning (AKA data cleansing) improves quality by fixing issues uncovered during assessment. Tasks may involve removing duplicates, fixing errors, handling missing values, standardizing formats, etc.
- Data Transformation - Here data is transformed into the required structure and format for analysis. Tasks involve changing data types, normalizing values, aggregating data, joining data sources, calculating new metrics etc.
- Data Enrichment - Optional enrichment adds value to existing data by merging in supplemental data from other sources. This provides deeper insights for modeling beyond what is available in the original data.
- Data Storage - After processing, data needs to be stored efficiently for easy access and analysis. This stage involves selecting the appropriate storage solution (such as databases, data warehouses, or data lakes) based on the size, type, and frequency of access of the data.
- Publishing Data - The final step involves making data accessible to end-users or systems that need it, while ensuring data privacy and compliance with regulations. Publishing can include creating dashboards, reports, or APIs for real-time access.

Data Wrangling Techniques
We'll now look at some of the various techniques that can be used in data cleaning, data transformation, and data enrichment.
Data Cleaning Techniques
Data cleaning is a crucial step in the data wrangling process. It involves identifying and fixing issues in the raw data so that it is accurate and consistent. Here are some key data cleaning techniques:
Fixing Missing Data - Missing data can skew analysis results. There are a few ways to deal with missing values:
- Delete rows or columns with many missing values if the information is not critical.
- Fill in missing values by imputing a logical value like the mean, median or mode.
- Use interpolation or a machine learning model to predict missing values.
Removing Duplicates - Duplicate data can also affect analysis. Identify and remove duplicate rows. Unique IDs can help spot duplicates.
Handling Outliers - Outliers are data points that are abnormally high or low. They can skew statistical models. Outliers can be capped at a maximum value or removed altogether.
Fixing Formatting Issues - Data should be formatted consistently. Fix issues like inconsistent capitalization, date formats, misspellings etc. Standardize formats.
Standardizing Data - Standardize data units and representations, like converting currencies or normalizing geographic data. This makes the data consistent.
Thorough data cleaning results in high-quality, reliable data for analysis. It's an essential step before processing and visualizing data.
Learn more about data cleaning:
 Team Zuar
Team Zuar
Data Transformation Techniques
Data transformation (also called data manipulation) is a critical step in the data wrangling process. It involves modifying the data in various ways to prepare it for analysis and visualization. Some key data transformation techniques include:
- Filtering - Filtering refers to removing data that is irrelevant or does not meet certain criteria. This helps focus the dataset on the variables and records that matter for the analysis. For example, filtering data to only include customers from a certain region or time period.
- Sorting - Sorting rearranges the data based on a particular variable, making it easier to understand relationships and patterns. Sorting by date, name, or amount provides structure and enables tasks like finding top customers or high-value transactions.
- Aggregating - Aggregating combines data points using operations like sums, averages, counts, etc. It condenses granular data into summary statistics for high-level insights. Common aggregates include total revenue, average order size, max daily users, etc.
- Joining Datasets - Joins combine data from multiple sources into unified datasets based on a common field like ID or date. This provides a more complete view by merging complementary information from different tables or files.
- Pivoting Data - Pivoting restructures data from rows into columns or vice versa to change its orientation. For example, pivoting transaction data with customers in rows into columns makes it easier to compare metrics across customers. Pivoting enables new analyses.
Learn more about data transformation:
Matt PalmerData Enrichment Techniques
Data enrichment is the process of augmenting existing data with additional information from external sources or by deriving new data points. Enriching data can provide deeper insights and improve the quality of analysis.
Here are some key ways to enrich data during wrangling:
Adding External Data - Merging datasets from different sources is a powerful way to enrich data. For example, customer transaction records could be combined with third-party demographic data or social media activity to get a 360-degree view of each customer.
Geographic data like ZIP codes can be merged with census records on income levels and other attributes. The key is to join datasets using common identifiers.
Adding Derived Columns - New columns can be added to existing data tables by applying calculations and transformations on the data.
Common examples include parsing strings to extract components, concatenating values from multiple columns, calculating metrics like profit margin, etc. Derived columns represent new data points that can provide additional analytical dimensions.
Categorizing Data Fields - Creating categories or bins for numerical data fields enables richer segmentation and analysis. For instance, age could be categorized into ranges like 0-17, 18-35, 36-50, etc. Item prices could be binned into low, medium, and high tiers.
Categorical data allows for evaluating trends across groups. Discretization techniques like equal-width binning or quantile binning can be applied to automatically categorize numerical data.

Data Wrangling Tools
There are many useful tools available to help with data wrangling tasks, from open source tools like R and Pandas, or end-to-end data wrangling platforms like the Zuar stack - Runner and Portal.
Zuar Runner automates the end-to-end data transformation process, saving time and eliminating the need for multiple pipeline tools. It offers flexible connectivity options and allows users to prepare data for analysis.
On the other hand, Zuar Portal provides a centralized platform for data access and sharing. Users can securely share insights from various sources, embed BI tools into existing applications, and enhance collaboration. Click here to start a free trial!
Together, Zuar Runner and Zuar Portal enable efficient and streamlined data wrangling processes.

Data Wrangling Next Steps
Data wrangling is a crucial step in the data analysis process. By taking the time to properly structure, clean, and enrich your data, you set yourself up for more accurate and impactful analysis down the road.
This processes is easier said than down, however. That's why we recommend teaming up with the experts - like the Zuar Labs team. Zuar Labs is a team of data superheroes that provides valuable assistance to businesses in data wrangling.
With their expertise in project management, implementation at scale, and advanced analytics, they help businesses effectively tackle the complexities of data preparation and transformation.
Zuar Labs offers services such as strategy and data architecture, data staging and modeling, data manipulation and hygiene, and data visualization. Learn more about our solutions and services by talking with one of our data superheroes:
Team Zuar Team Zuar
Team Zuar
