
An index for a SQL database table is not unlike the index found in a book. When an author writes a non-fiction book, the author considers essential topics and information that a reader will quickly access. The book’s index enables readers to quickly ‘scan’ the index to find topic(s) of interest and be swiftly directed to that location. In the case of an index for a table, this premise is similar. When a user queries a database, if a table is indexed appropriately it will aid in the execution plan to retrieve that data as quickly as possible.
An index aids in the execution of a query when conditions are placed in the query. In other words, when you add a WHERE clause in your SQL, the indexes associated with the table(s) can improve the execution time and cost. Continuing with the book analogy, consider that you are looking in the index for a specific topic. It is analogous to “select something from the book where the topic is …”. As your conditions become more complex, indexes can dramatically improve your SQL’s performance.
Considerations
As with most things, nothing is without cost. Keep in mind that SQL indexes are data stored in the database. Therefore, there is a ‘cost’ associated with indexes. Creating indexes will take up storage space in your SQL database. While the space required for indexes is minimal and the benefits of indexes can be profound, it is worth remembering this.
Also, when people begin using indexes in SQL, their first reaction may be to index everything. However, this is not a best practice. Remember the analogy of indexing for a book. If everything in the book is indexed, it becomes challenging going through the indexes. It’s the same with SQL databases. The goal is to ensure query execution is as efficient as possible. Therefore, using indexing judiciously and based on query requirements should always be kept in mind. A best practice is to create indexes to match those items used in your conditions (WHERE clause) most often.
While most SQL indexes require manual creation, there are times when indexes are created automatically. Primary keys are one such example. When a column is designated as a primary key, the database will automatically consider this a unique index.

The B-Tree Index
While there are different types of indexes, the most commonly used across various database platforms is the B-Tree index. The B-Tree (short for Balanced Tree) index is an algorithm used by a database to “balance” the indexes through node-and-leaf structures. The B-Tree index works behind the scenes to ensure that indexes are maintained and balanced.
It’s worth noting that understanding the inner workings of how B-Tree indexing works is somewhat academic. While I wouldn’t suggest it’s not essential, I would say it will not be of concern in most instances. The balancing aspect of the B-Tree index is done for us by the database. Nice!
For reference, below is an example of the B-Tree index.

In the following discussion, all code examples will be using the B-Tree Index. Because the B-Tree index is the default index type to use, explicitly declaring an index as a B-Tree is not required.

Before We Begin
Note: I am using PostgreSQL in all examples. Zuar uses PostgreSQL extensively.
Because indexes and indexing data in tables are directly associated with improving query performance, it is equally important to understand and utilize the results from your query’s execution plan. By reviewing your query’s execution plan, you will see the impact of the indexes you add to your table. In PostgreSQL, the EXPLAIN ANALYZE keywords preceding the SQL statement will provide the execution plan.
In the examples, I will be using two tables. The first table, called “mock_data_big” is a table with no indexes. The second table, called “mock_data_big_idx” will be used to compare the impact when indexes in SQL are added. Both these tables have one million rows of data. The data is the same in both tables.
Here’s the structure of the table:
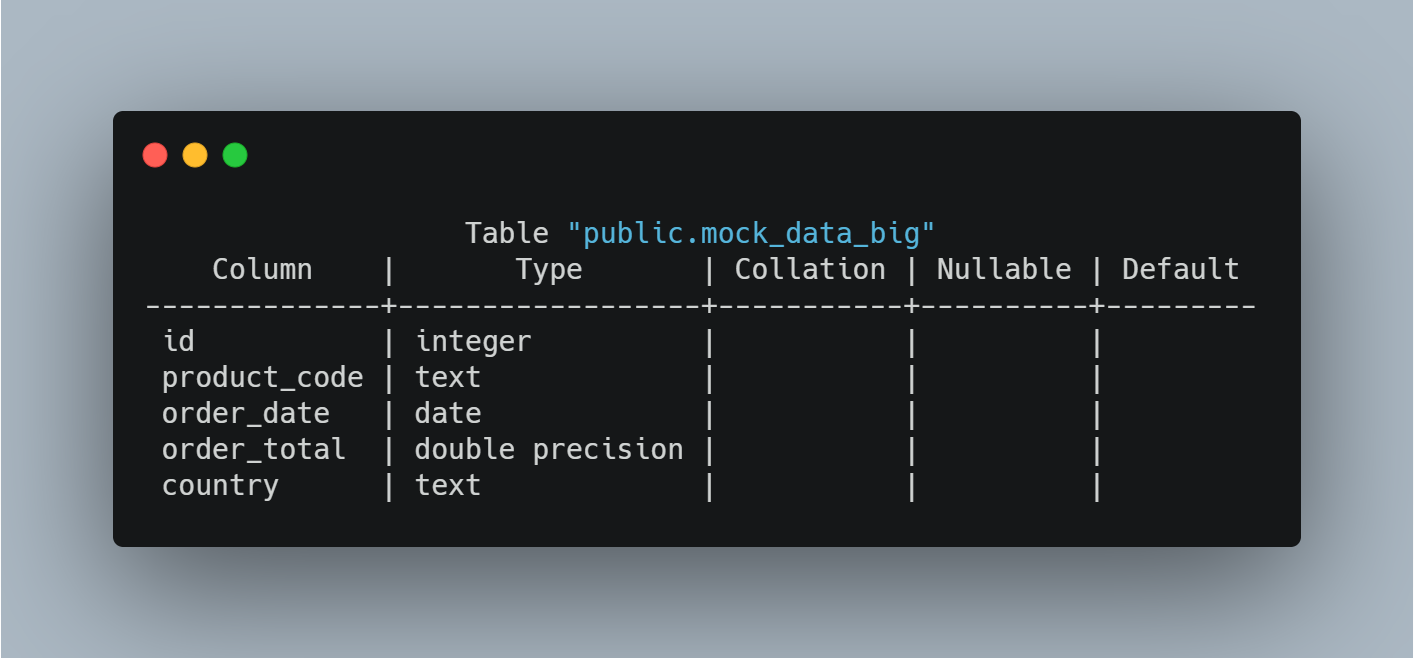
Indexes in Action
Unique Index
In the first example, a unique index is added to the table. The unique index provides an index for each unique value and is usually associated with primary keys. As previously mentioned, when creating a table a unique index is created by default. But in this example the unique index is added after the table is created.
Here’s the SQL for adding a unique index to the table and the resulting change to the table.

Notice that the index is listed at the bottom, and the word “unique” is included.
Now, let’s see the impact by running a simple SQL statement against the tables. First, the non-indexed table:

And the indexed version:

When comparing the cost of the two queries:
- The non-indexed table required a full table scan (in PostgreSQL it is called a seq scan).
- The execution required reading over 300,000 rows to find the answer
- The execution time was 80 milliseconds
- The indexed table used an index scan. It used the index to find the data requested.
- Reading rows unnecessarily was avoided entirely.
- The execution time is .1777 milliseconds. A HUGE difference!
Let’s now see the impact when doing an aggregate query. It is still a simple example, but the condition will change a little. The SQL will get the sum of the order_total field based on the ID.

And the indexed:
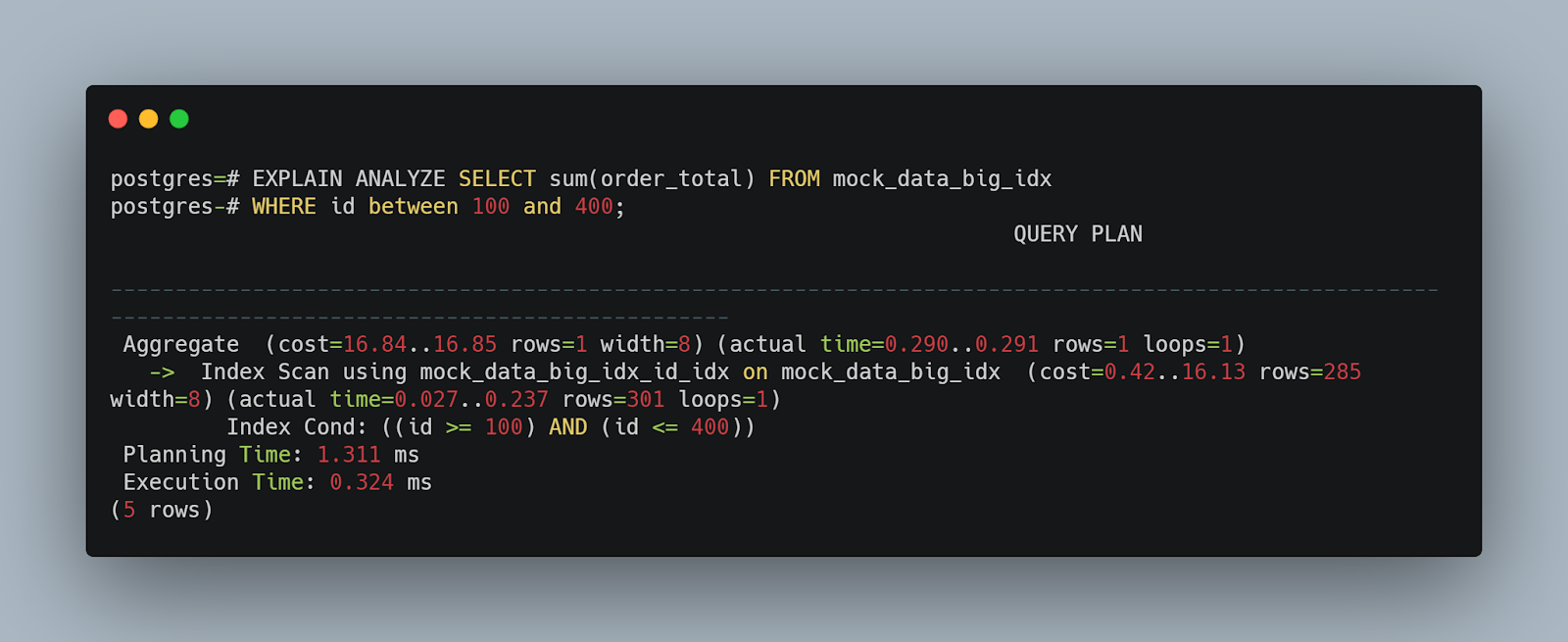
Again, notice that the non-indexed table required a full table scan while the indexed table could use the index to return the results. Also, see the dramatic cost reduction. Lastly, the index scan reduced execution time from 87 milliseconds to .324 milliseconds.
Non-Unique Index
Indexes do not need to be unique. If data is not unique but frequently used in the WHERE clause, a non-unique index is ideal. A non-unique index is the default index that is created. To create one, you just leave the word “unique” out of the SQL.
Here is the SQL for adding an index to the country field of the table.

Because non-unique indexes will group the data into “heaps” behind the scenes, the execution plan will change. However, the creation of the index will still be a huge benefit.
Recall that the point of an index is to aid in improving performance associated with conditions in the SQL. So, let’s change the filter to reference the country.
As before, first the non-indexed table:
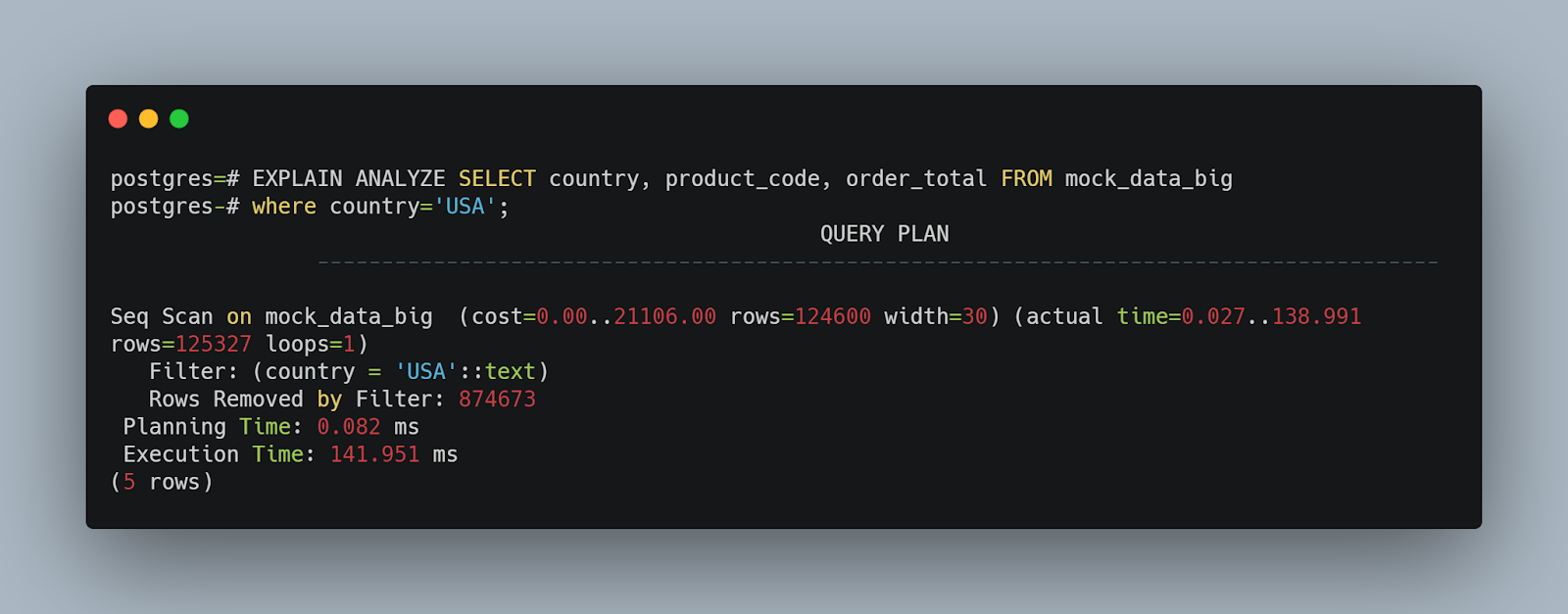
And the indexed version:

Notice with the indexed version, the execution plan now uses a bitmap heap scan. This execution plan is better than a full table scan. Unfortunately since the index is not unique, an index scan cannot be used. Execution time was reduced from 141 milliseconds to 41 milliseconds. The query’s cost was also cut in half.
Multiple indexes, once created, can be leveraged as well. Behind the scenes, the execution plan will reference the indexes and use them to serve the execution best. When the execution plan is formulated, the index that will provide the most benefit is used. Therefore, based on the query, if a unique index provides better performance then the index scan will be used first. If not, a bitmap heap scan will be used.
More Advanced Index Options
Multi-Column Index
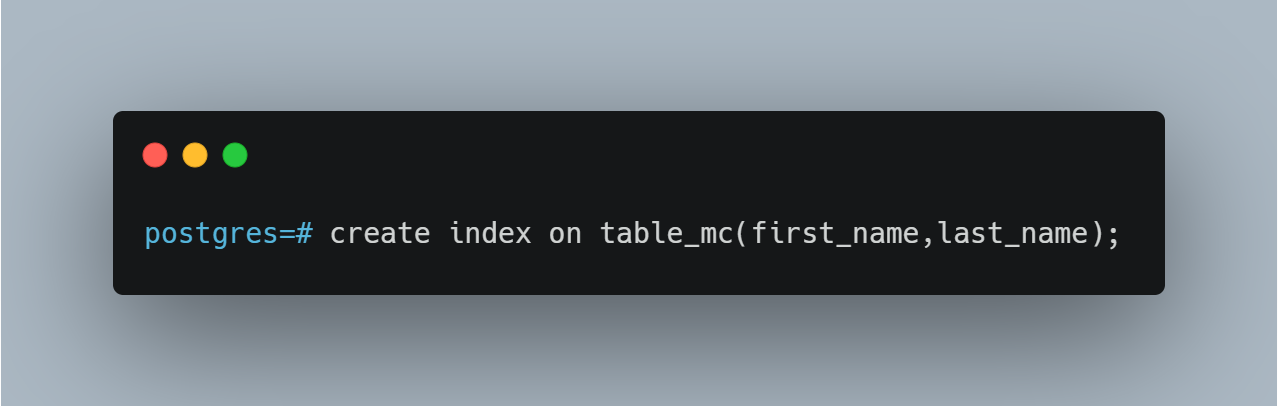
Indexes do not need to be just attached to a single field in a table. If you have a query that will often use the same columns in the WHERE clause, using an “AND” statement, consider creating a multi-column index. For example, if you have two columns, such as first_name and last_name, you could create an index that references both columns.
Sorted Index
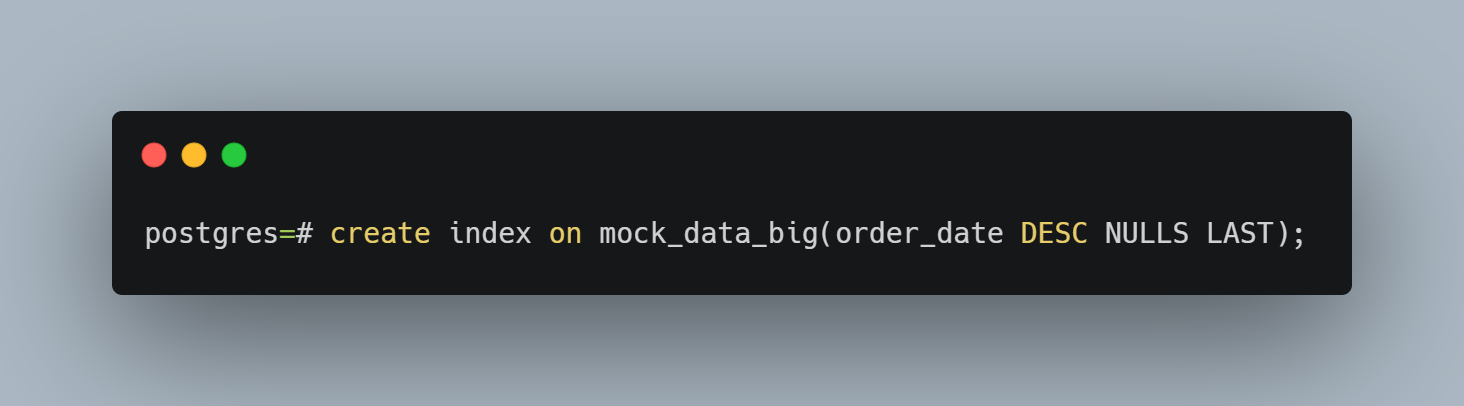
There may be cases when you want to have your index sorted. By default, an index is sorted in ascending order. If you are frequently looking for the latest data, setting the sort order to descending may be of value. Here’s the syntax for doing just that:
Expression-Based Index
If you are frequently going to have an expression in your condition, an index can also be created based on that expression. Using the first and last name as an example, if you often query WHERE (first_name || ‘ ‘ || last_name)= “some name”, an index can leverage that expression.

Partial Index
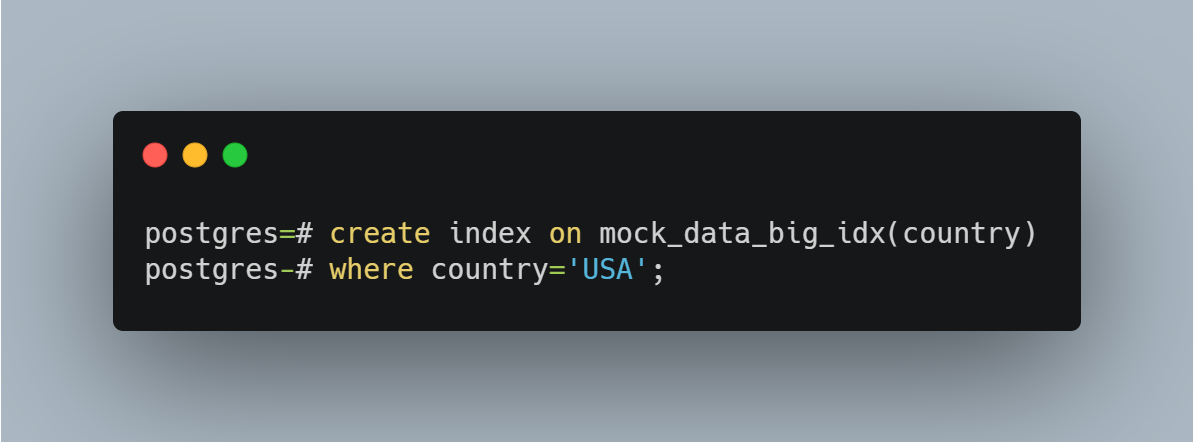
A partial index is designed to index only data deemed worthy of being indexed. For example, if you are frequently only going to query data from the USA from the country column, this can be set. Thus, it excludes any data associated with countries other than the USA from the index. This is done by adding a WHERE clause to the index.
Other Index Types
So far we’ve only discussed one type of index, the B-Tree. While B-Tree indexes are used most often and have the most opportunity for application, there are other types of indexes. PostgreSQL has a few different types of indexes, for example:
Hash Index
The hash index has a somewhat limited use case. The hash index can only be used in instances where you are setting the condition to equal something. For example, if you have a SQL statement stating WHERE id=5, a hash index would work. However, hash indexes will not work with conditions that would use <, >, between, in, etc.
GIN Index
The GIN (Generalized Inverted) index is used and useful for instances where multiple values are stored in one field. An example would be a field that uses an array data type. The scope of this index type is narrow in application.
BRIN Index
BRIN (Block Range Index) is like B-Tree indexes. However, due to how it works behind the scenes, they are faster and take up MUCH less space. However, BRIN indexes are used for very large (e.g. 10 million rows +) datasets and queries expected to return huge amounts of data. If your tables are not exceedingly large, then BRIN indexes will be slower than B-Tree.
GiST Index
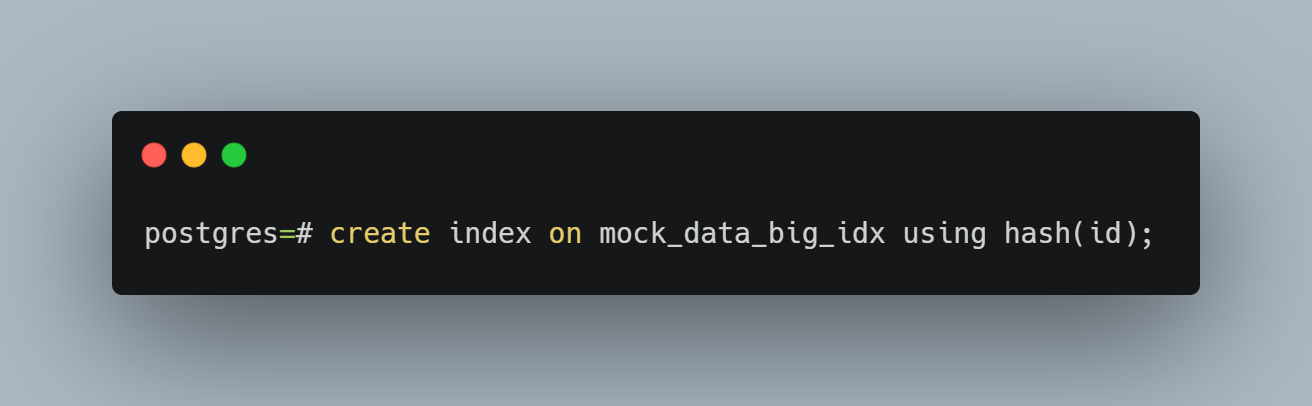
GiST (Generalized Search Tree) index is helpful for data that doesn’t fit into the typical data paradigm, including text documents, geometric data, images, etc. For these index types they're implemented using the same syntax. This is done by creating the index and including the keyword 'using'. In the example below, a hash index is created. The same syntax is used when creating a GIN or GiST index, but the word 'hash' would be replaced by GIN, BRIN, or GiST.
Last Thoughts
SQL indexes also have many options and arguments that are worth reviewing. PostgreSQL, for example, has excellent documentation that reviews the options associated with index creation.
On a similar topic, analyzing data across business solutions shouldn't be so difficult! With Zuar's Runner solution, you can automate data flows from hundreds of potential sources into a single destination like PostgreSQL. Transport, warehouse, transform, model, report, and monitor: it's all managed by Zuar Runner. Plus, our experts will ensure your deployment is fast and smooth. Learn more about Runner.


