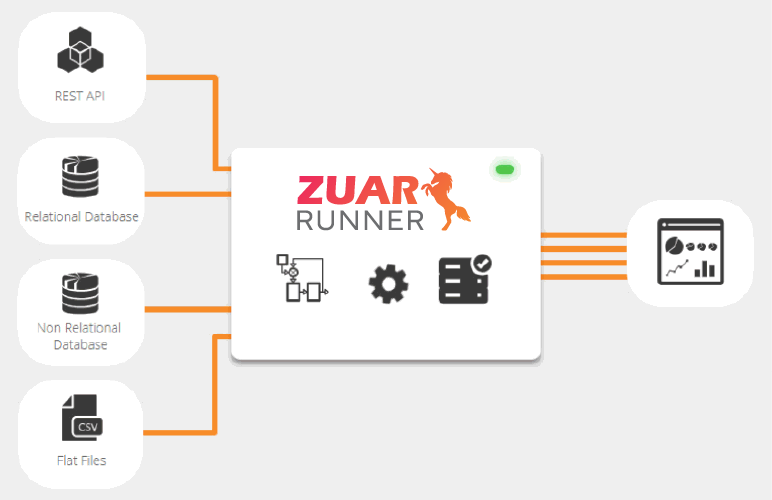
The Types of Modern Databases
Aren’t sure which modern database is right for your organization? Zuar explores the different database models and their benefits.


Overview
Today, databases are everywhere. Often hidden in plain sight, databases power online banking, airline reservations, medical records, employment records, and personal transactions.
But what is a database? A database is a shared collection of related data used to support the activities of a particular organization. It can be viewed as a repository of data that is defined and accessed by various users (Database Design 2nd Ed, Watt & Eng). This definition is inherently broad: in practice, databases differ by intended purpose—each is dependent on the type of data stored and the type of transactions that occur.
Is data most frequently being read or written? Does data need to be accessed by row or column? How can the database management system ensure control over data integrity, avoid redundancy, and secure data while performing optimally? This article will present and assess modern databases, assisting in the research and selection of an optimal system for information storage and retrieval. For assistance with implementing solutions to your database, reach out to our team at Zuar.

Selecting the Optimal Database
There are a plethora of characteristics to evaluate when selecting the ideal database for your team/project. The “right” solution will be the one that best serves your needs and intended use. Characteristics like business intelligence optimization, data structure, storage type, data volume, query speed, and data model requirements play a role, but the best solution will be one tailored to your use-case.
A good starting point for selecting the optimal database is to understand the different database structures:
- Hierarchical: A hierarchical database utilizes a parent-child relationship to organize and manage data in a tree-like structure. In this type of database, the schema of a hierarchy has a single root.
- Network: A network database enables a child record to link to several parent records, allowing multi-directional relationships. This allows several records to link to the same owner file.
- Object-Oriented: Object-Oriented Databases (OODBs) are used for complex data structures to reduce overhead and flatten the object for storage. The structure of the objects determines the relationships between objects.
- Relational: A relational database structures the data as a two-dimensional array. The data is placed into tables and organized by rows and columns. Relational databases use keys within a column to order and create relationships to other tables.
- Non-relational: A non-relational database doesn’t use a tabular schema that most database systems use. Instead, it utilizes numerous formats for database design, enabling more flexibility and scalability in the design to accommodate different data types.
Most organizations opt for a relational database leveraging SQL (RDBMS—relational database management system) or the less-common non-relational database (like NoSQL).

Relational & Non-Relational Systems
Relational Database Systems (RDBMS)
A relational database (or SQL database) stores data in tables and rows, also referred to as records. The term “relational database” is not new—it's been around since the 1970’s and was coined by researchers at IBM. Some of the most popular relational database systems include Postgres, MySQL, SQLite, and Microsoft SQL Server.
A relational database works by linking information from multiple tables through the use of keys, which are identifiers assigned to a row of data. The unique identifier, a “primary” key, can be attached to a corresponding record in another table (when the two records are related). This attached record is then known as a “foreign” key. The primary key (PK), foreign key (FK) relationship allows the two records to be “joined” using SQL.
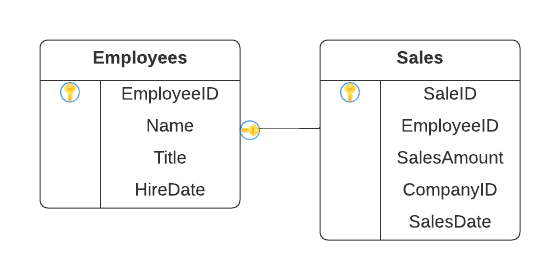
A significant advantage of the RDBMS is “referential integrity,” which refers to the consistency and accuracy of data. Referential integrity is obtained through proper use of primary and foreign keys.
Non-Relational Databases
Non-relational or NoSQL databases are also used to store data, but unlike relational databases, there are no tables, rows, primary keys, or foreign keys. Instead, these data-stores use models optimized for specific data types. The four most popular non-relational types are document data stores, key-value stores, graph databases, and search engine stores.
Learn more about the differences between SQL and NoSQL:
 Team Zuar
Team Zuar

Popular Modern Databases
Snowflake
Snowflake is an analytic data warehouse provided as Software-as-a-Service (SaaS). The Snowflake data warehouse uses a new SQL database engine with a unique architecture designed for the cloud.
To the user, Snowflake has many similarities to other enterprise data warehouses, but contains additional functionality and unique capabilities. Snowflake is a turn-key solution for managing data engineering and science, data warehouses and lakes, and the creation of data applications—including sharing data internally and externally.
Snowflake provides one platform that can integrate, manage, and collaborate securely across different workloads. It also scales with your business and can run seamlessly across multiple clouds.
Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift is a cost-effective solution for:
- Running high-performance queries to improve business intelligence.
- Generating real-time operational analytics on events, applications, and systems.
- Sharing data securely inside and outside the organization.
- Creating predictive analytics of the data in your data warehouse.
PostgreSQL
PostgreSQL, usually referred to as Postgres, is a free, open source, object-relational database management system (ORDBMS) emphasizing standards compliance and extensibility.
PostgreSQL has earned a strong reputation for its proven architecture, reliability, data integrity, robust feature set, extensibility, and the dedication of the open-source community behind the software to consistently deliver performant and innovative solutions.
There are many benefits to a PostgreSQL database, not limited to:
- Custom functions in a host of languages.
- A wide array of data types and the ability to construct new types.
- Robust access control, authentication, and privilege management.
- Support for views and materialized views.
MySQL
MySQL is also a free, open-source RDBMS. MySQL runs on virtually all platforms, including Windows, UNIX, and Linux. A popular database model that is used globally, MySQL offers a multitude of benefits:
- Industry leading data security.
- On-demand flexibility that enables a smaller footprint or massive warehouse.
- Distinct storage engine that facilitates high performance.
- 24/7 uptime with a range of high availability solutions.
- Comprehensive support for transactions.
Microsoft SQL Server
Microsoft SQL Server is an RDBMS database that supports a wide variety of analytic applications in corporate IT, transaction processing, and business intelligence.
Organizations can implement a Microsoft SQL Server on-premise or in the cloud, depending on structural needs. It can also run on Windows, Linux, or Docker systems. As part of the Microsoft toolkit, many Microsoft’s applications and software integrate well with Microsoft SQL Server.
Does your enterprise need a more comprehensive data strategy? Contact Zuar for a data strategy assessment.
Related article:


Other Database Options
Key-Value Stores
Key-Value Stores, such as Amazon DynamoDB and Redis, are straightforward database management systems that provide fundamental services for retrieving the value associated with a known key—they store only key-value pairs.
The simplicity of key-value stores makes these database management systems particularly well-suited to embedded databases. They shine in situations where stored data is not particularly complex and speed is of the utmost importance. The most significant advantages are speed, scalability, and flexibility.
Wide Column Stores
Wide Column Stores, such as HBase, Scylla, and Cassandra, are all schema-agnostic systems that enable users to store data in tables, column families, or a single row containing a multi-dimensional key-value store.
These types of solutions are designed with the intent of scaling efficiently to manage potentially petabytes of information. They are well suited to distributed systems and can handle complex networks with ease.
Even though these solutions are schema-free, wide column stores like Cassandra and Scylla use an SQL variant called CQL for data manipulation, making them accessible to those already accustomed to RDBMS.
Wide Column Stores are best suited for organizations that need:
- Data extraction that utilizes row keys.
- High write speeds.
- Scalability to handle massive data volume.
Document Stores
Document Stores, like Couchbase and MongoDB, are schema-free systems that store data in the form of JSON documents. Document stores are similar to wide column stores or key-value pairs—the document's name is the key and the contents of the document are the value.
In a document store, the individual records are unstructured, contain differing value types, and can be nested. This flexibility allows them to be well-suited to manage semi-structured data across distributed systems.
Document Stores are best suited for applications that require:
- Support for unstructured or semi-structured data.
- Pre-computed or aggregated data.
- Efficient pagination of query results.
Graph Databases
Graph Databases, like Neo4J, represent data as a network of related nodes or objects to facilitate graph analytics and data visualizations. An object or node in a graph database contains free-form data that is connected by group according to labels and relationships.
Graph-oriented data-stores are created with an emphasis on demonstrating associations between data points. Hence, they’re useful for analyzing connections between nodes and frequently used in:
- Fraud prevention and network analysis on bad actors.
- Social networks and user relationships.
Search Engines
Search Engines, such as Solr, Splunk, and Elasticsearch store data using schema-free JSON documents. These are very similar to document stores, but with a higher emphasis on semi-structured or unstructured data accessibility via text-based searches.
There are several benefits for using a search engine database:
- Data exploration and analysis without coding requirements.
- Generate training, testing, and validation data splits faster and cheaper.
- Custom map and shape a variety of data and content types.
- Search-driven analytics and B.I.

Strategize Before You Choose Your Database
We at Zuar understand that there are a variety of technical challenges and nuances to consider when selecting a modern database technology. The Zuar team has years of experience working with different database technologies and solving the data challenges of our clients. Contact us if you need help choosing the best option for your specific use case, or for a free data strategy assessment!