What is Data Integration?
Data integration is the process of obtaining data from multiple sources and combining it to build a single 'unified' view. Data integration is a solution to the problem of data silos—disparate datasets that are difficult to utilize together.
Modern data teams have more data than ever before, but such data is increasingly spread across various systems and platforms, sometimes in incompatible formats. Data integration allows businesses to unlock value by combining data in a cohesive manner.
Thus, a data integration pattern is a standardized method for integrating data, whether syncing data between multiple sources, copying data to a target system, or consolidating data into a single store.
The five most common data integration patterns are:
- Data Migration
- Broadcast
- Bi-directional Sync
- Correlation
- Aggregation
Click here to learn how to implement these patterns with a data integration consultant.

Migration
Data Migration is the movement of data from a source to a destination system at a single point in time. A migration consists of the source system, a filtering criteria to determine which data will be migrated, a set of transformations that will run on the data, a target system where data is inserted, and checks to ensure the migration completed successfully.
Migration is essential for maintaining data and retaining independence from vendor lock-in. Without the ability to migrate data, we’d lose any and all collected data when switching tools. In that regard, the ability to migrate data is an essential requirement in any business decision.
Related article:
 Greg Rossi
Greg Rossi
Broadcast
Broadcast is the movement of data from one source to several destination systems continuously (real-time or near real-time). Similar to migration, broadcast moves data in a single direction. Unlike migration, broadcast is transactional—only data that has arrived since the last transfer is processed. Hence, broadcast is highly efficient: it only needs to process the latest arriving messages on each run.
Broadcast ensures a single source is replicated across multiple destinations simultaneously, in real-time. It is designed to operate as efficiently and quickly as possible while being highly reliable to avoid losing critical streaming data.
Bi-Directional Sync
Bi-directional sync is the combination of two datasets from different systems to perform independently while existing as a separate dataset. This differs from migration or broadcast, since data is being moved in more than one direction.
This pattern is extremely valuable for businesses who need access to both individual and combined views of similar data. It can also be useful when two silos of data must be used together for a single business goal. The concept of Reverse ETL comes to mind: when multiple business tools need to communicate, a bi-directional sync pattern can be used to keep mission-critical data up-to-date across multiple systems. For example, keeping Salesforce data populated with descriptors from a warehouse while importing that raw data into the warehouse, or escalating Salesforce cases to development issues in a Jira Salesforce integration and keeping both sides updated till the problem on the customer side is resolved.
Correlation
Correlation is similar to bi-directional sync, but only performed with data relevant to both systems. That is, it only considers the intersection of two data sets (items naturally occurring in both) when performing a synchronization.
The key difference is that correlation removes irrelevant data from the union process, making this pattern more simple and efficient. Correlation is ideal when two systems want to share records that naturally exist in both datasets.
This can be particularly useful when having extra data does more harm than good. For example, a hospital might want patient records from other doctors, but only for patients who’ve visited their facility. Including all patients would be superfluous and confusing, so correlation would be used to find the intersection of existing patients and records outside the hospital.
Aggregation
Aggregation is the process of merging data from many systems to a single, target system. This pattern provides a centralized view of real-time data from multiple systems and ensures data is not duplicated.
The consolidated nature of aggregated data is optimal for data analysis and business intelligence. The aggregated pattern can be valuable when creating APIs to obtain data from multiple systems and deliver it in a single response. Similarly, aggregation can ensure that data lives in a single system, but is amalgamated from many others.
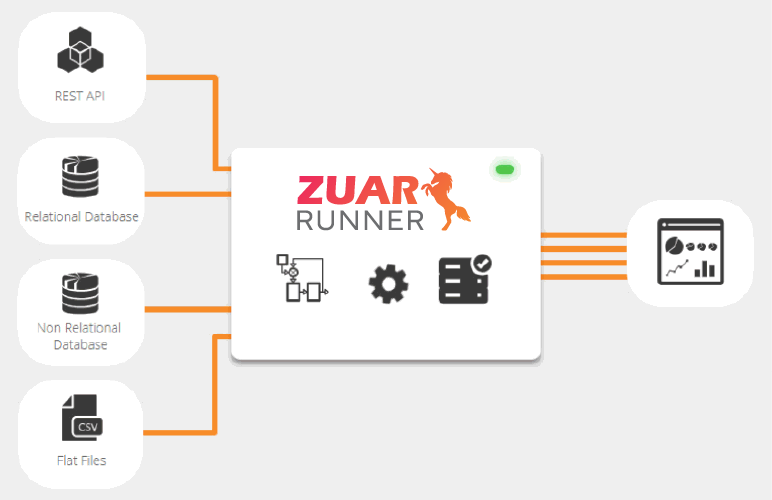
ETL/ELT solutions employ aggregation to combine data from different sources into a single location, such as a data warehouse. One such solution is Zuar's Runner data pipeline platform, which manages the process from end-to-end (unlike many other solutions which only manage a portion of the process).

Implementation
Finding the right tech solutions for the type of data integration that your organization needs can be challenging. Zuar's data integration services can help you through the entire process, from strategy formulation through implementation and beyond. We can also take you through our free data strategy assessment to see if Runner, Zuar's data pipeline solution, is a good fit.