Intro
Data driven organizations are built on clean, reliable datasets and foundational analysis. These assets can provide tremendous value, but they rely on quality data and production-grade data systems.
Improving data quality starts with the very first step in the transformation process: importing data into the warehouse. These imported datasets form source data for the following transformations and, ultimately, underpin the finished data product.
Today, we’ll be discussing sources in the popular data transformation tool dbt (data build tool— yes, all lowercase!).
To understand sources, we must first understand dbt: the tool, its functionality, and implementation. After a brief overview of dbt, we’ll dive into what dbt sources are, how they work, and how you can use them to advance your data warehouse.

What is dbt?
dbt is short for data build tool, which summarizes its functionality quite nicely: dbt is a transformation workflow that helps to organize programmatic data warehouse manipulations.
Created by Fishtown Analytics, dbt has evolved into a venture-backed data giant through its paid offering dbt Cloud. The CLI (command line interface) that underlies dbt Cloud, dbt Core, is still free, open-source and used by many (though it lacks the GUI and advanced functionality of Cloud).
At its simplest, dbt is a way to manage a collection of SQL transformations that define a data warehouse. Under the hood, dbt contains much more: a code compiler, dependency management system, documentation framework, testing infrastructure, and jinja implementation mechanism.
Ultimately, dbt’s functionality serves to optimize data workflows and provide robust analysis and production-grade, version-controlled data systems.

How does dbt work?
Overview
dbt acts as an orchestration layer, which sits on top of a data warehouse and organizes transformations. If you’ve heard of the popular tool Apache Airflow, the concept of dbt should be familiar, though the tools differ in a number of ways.
dbt accepts SQL and jinja transformations, organizing them into DAGs (directed acyclic graphs) that are then executed against a data warehouse.
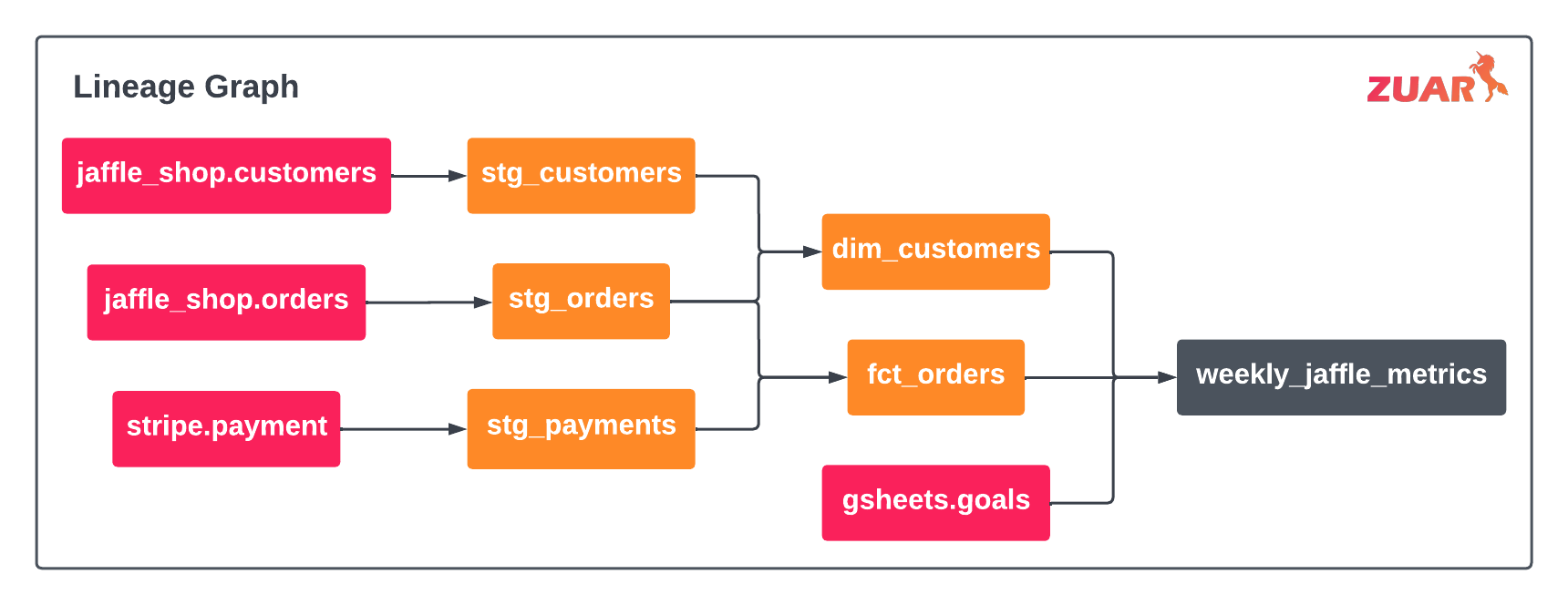
By defining references, dbt can track model dependencies. For example in the figure above, stg_customers contains a ref(‘jaffle_shop’, ‘customers’)— this tells dbt that stg_customers is downstream from our source.
Simple but powerful, references are key to managing complex data workflows and dependencies, since they determine the order in which models are executed.
As mentioned, dbt contains a wealth of additional functionality. But to understand sources, we need only know that dbt is an orchestration tool, programmatically executing templated SQL through the use of references and compiled queries.
dbt project structure
While a dbt project can be structured in any number of ways, dbt best practices dictate a practical approach to building projects.
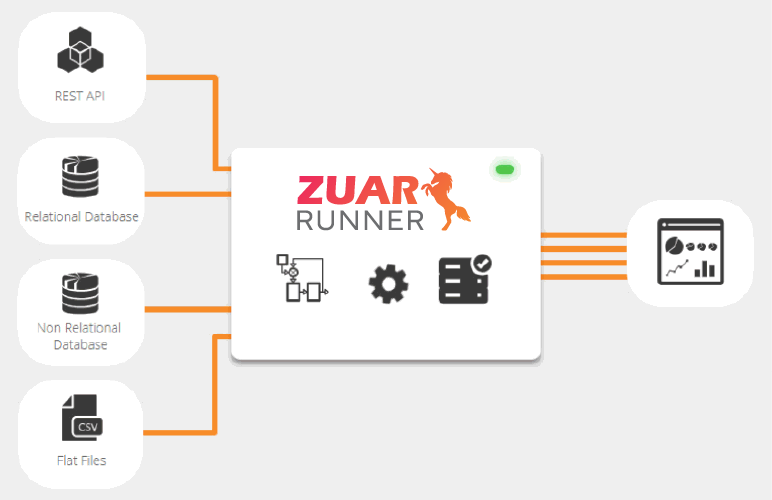
First, sources are imported into a warehouse and declared. Since dbt is focused on transforming data that already exists in a warehouse, it’s up to the warehouse maintainer to pull in relevant data through extract and load processes or other means.
dbt does offer seed functionality for loading CSVs, but it is only recommended for smaller datasets. For larger data sets, tools such as Zuar's data pipeline solution Runner could be a better fit.
Once sourced, raw data is then staged. Staging provides a temporary area for minor transformations, and helps to mitigate common data pitfalls like upstream changes, inconsistent formats, and more.
Learn more about data staging:
 Matt Palmer
Matt Palmer
Finally, data is cleaned and larger transformations are applied. The resulting tables are exposed to analysts and stakeholders for consumption.
Since sources are the foundation on which the warehouse is built, it’s essential to invest in architecture and testing. Properly configuring sources is essential to use dbt to its fullest extent. Now that we understand the complete dbt pipeline, we can discuss sources in-depth.

What are dbt sources?
Sources make it possible to reference data objects in a dbt project structure. By declaring tables as sources in dbt, you can directly reference them in your models, test assumptions about source data, and calculate “freshness” (the recency of loaded data).
Sources are defined in yaml files, a format common in dbt, nested under a sources key. Here’s an example source from the dbt docs:
Again, these are for tables that already exist in a warehouse or will be seeded using dbt. Once defined, sources can be referenced from a model using the source function:
dbt will compile these jina templates to the full table name upon execution, creating proper SQL references and a dependency:
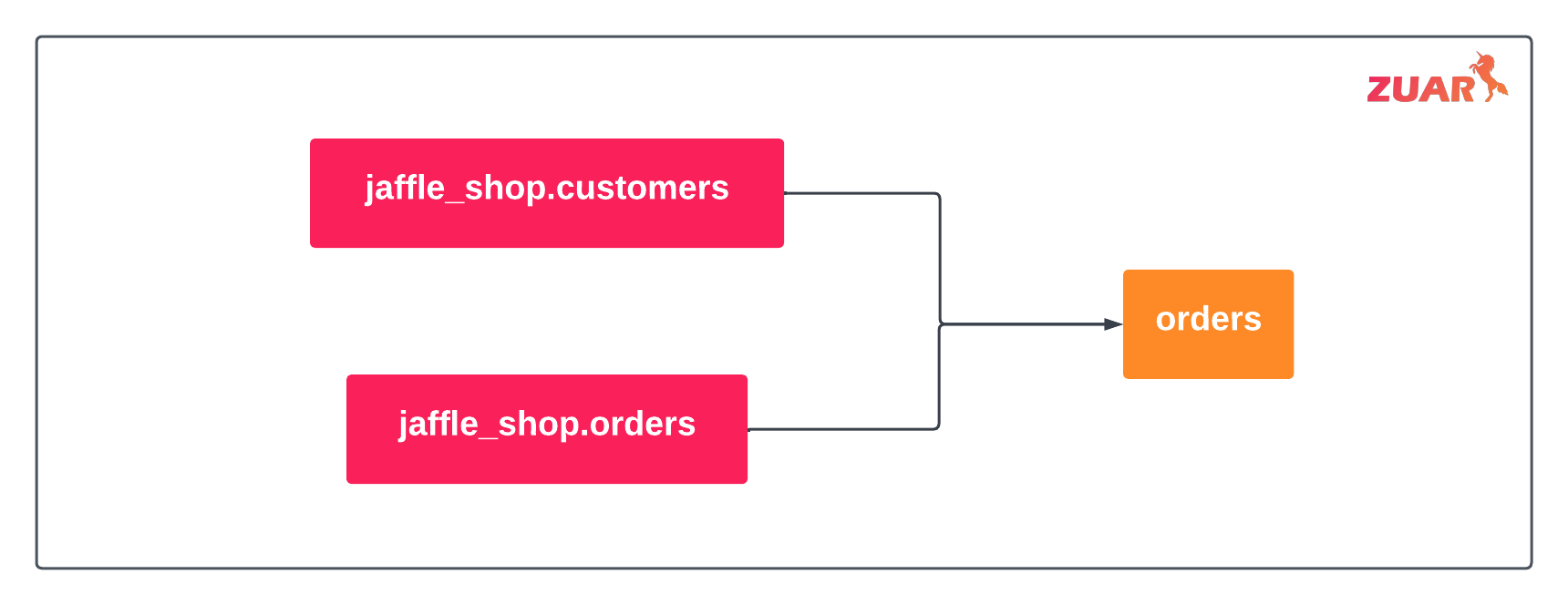
Thus, sources create the foundation for all subsequent transformations in dbt— by establishing source data, enable metadata, lineage, and dependency tracking for all downstream tables.

Why use dbt sources?
Sources bring more benefit than simply creating references and dependencies. By declaring sources in dbt, we can add metadata that is rendered to a part of dbt’s document site and create tests to ensure data consistency and freshness.
All versions of dbt ship with project documentation functionality (see dbt’s example site). Declaring sources and references allow dbt users to take full advantage of this.
Additionally, not all data loading tools report on the status of their transformations. Such tools may silently fail, resulting in stale or incorrect data. Using dbt sources allows us to declare tests and assertions on imported data: for example, checking columns for uniqueness, validating non-null values, and ensuring data freshness.
Data observability is crucial to producing consumable data and it starts at the source— hence the power of dbt sources!

Make it Easier to Work With dbt
While dbt is a powerful tool, particularly for developers who like writing SQL, it's automation capabilities are limited. That's where an automated data pipeline solution, such as Zuar's Runner platform, can fill the gap.
Runner allows developers to automate dbt scripts, potentially saving hundreds of hours of manual tasks.
If you are considering implementing dbt, or are currently utilizing this tool, we recommend using it in conjunction with Runner to create a robust, scalable data pipeline. Schedule a free data strategy assessment to see if Runner is a good fit!