Export to Flat File¶
Zuar Runner can output data to delimited (e.g. comma, tab, pipe, etc) flat files.
Outputting to a flat file with a custom IO job¶
Here’s an example SQL database table we will export to CSV using a modified Query job.
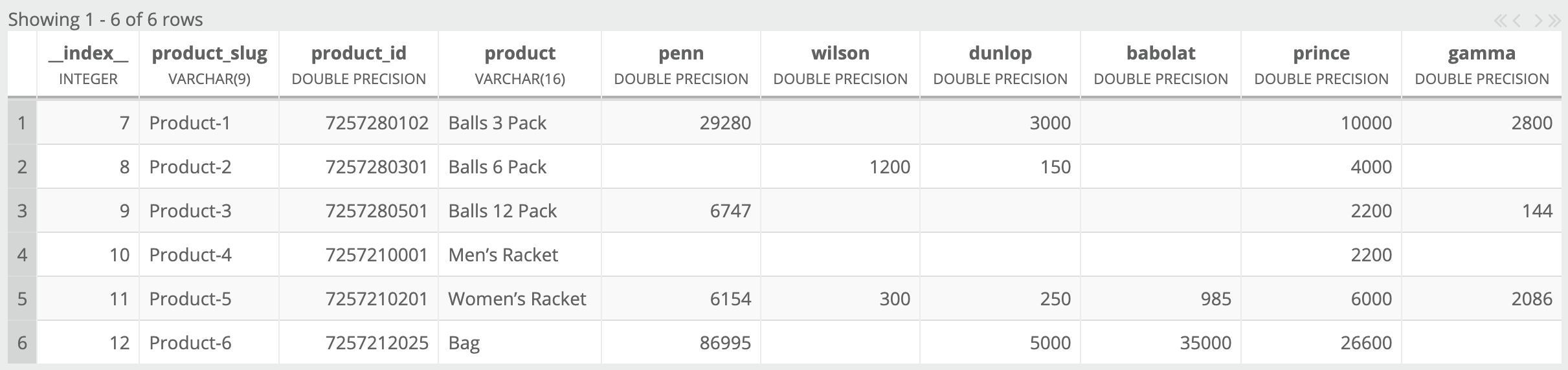
Sample data for toCSV
Use the Generic plugin to create a custom IO job.
Set the type to io.
Use the job config below:
{
"input": {
"dbo": "postgresql://db/analytics",
"query": [
"SELECT * from excel.tennis_products;"
],
"use": "query.io#QueryInput"
},
"output": {
"path": "/var/mitto/data/output_{year}_{month}_{day}.csv",
"delimiter": ",",
"use": "call:mitto.iov2#tocsv"
},
"steps": [
{
"transforms": [
{
"rename_columns": false,
"use": "mitto.iov2.transform#ExtraColumnsTransform",
"include_empty_columns": true
}
],
"use": "mitto.iov2.steps#Input"
},
{
"transforms": [
{
"use": "mitto.iov2.transform#FlattenTransform"
}
],
"use": "mitto.iov2.steps#Output"
}
]
}
Job Config Keys¶
The input below is used for a Query job, but the
key components when exporting to a flat file are the output and the
steps. The input can be an input from any IO job.
input¶
Contains the database and query: SELECT * from excel.tennis_products;. Any
SELECT statement will work. Zuar Runner will use the column names for headers.
output¶
Contains options that affect the output file the job will create, including the output path, and the delimiter to use.
Output path: /var/mitto/data/ is the top-level directory in Runner’s file system. Files
in this directory (or sub-directories) will be visible in the Files page within Runner’s admin UI.
Delimiter: In this example we’re using , as a delimiter. For tabs use: \t
Exclude the file header: use write_header: false in the output section to
prevent column names from being included in the output file.
The output code uses the Python csv package. Any key word arguments can be
passed to csv.writer
(https://docs.python.org/3/library/csv.html#csv.writer ).
Path Variables¶
It is possible to include date and time variables in your output
path/filenames. In our example
/var/mitto/data/output_{year}_*{month}_*{day}.csv, the strings inside
curly brackets {} are variables; in this case the current year, month and
day.
Available Variables:
year - The current year (2020)
month - The current month (05)
day - The current day (26)
hour - The current hour (07)
start_time - Date and time the job started (05-26-2020T07:30:30)
last_year - 2019
last_month - 04
last_day - 25
last_hour - 06
next_year - 2021
next_month - 06
next_day - 27
next_hour - 08
week - The week number for week of the year. (01-52)
You can also pull out values from the last and next values:
Yesterday’s day is
{last_day.day}, month is{last_day.month}, and year is{last_day.year}.
These are more complex examples using Python’s **strftime** on date values:
Today is
{now:%A}, {now:%B} {now:%d}, {now:%Y}One year ago from today was
{last_year:%c}The time is
{now:%X}The time is
{now:%I}:{minute}:{second} {now:%p}
steps¶
Any steps for processing the data. The steps included in the example above are
default steps which will include empty columns (via "include_empty_columns":
true) and will not rename columns (via "rename_columns": false).
Resulting Flat File¶
The resulting flat file is created on Zuar Runner’s file system.
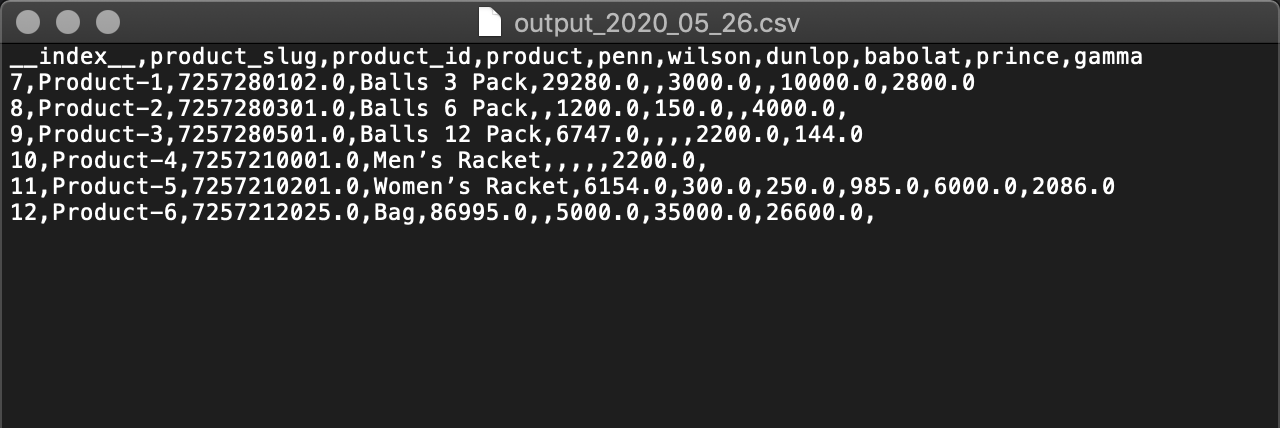
Output from toCSV job
You can download the file manually or use another job (e.g. email, Rclone, command line, etc) to send the file elsewhere automatically.